Я слышал от разных людей, что мои предыдущие статьи (тут и тут) об общих задачах Excel в pandas оказались полезными. В этой статье мы продолжим эту традицию, проиллюстрировав различные примеры индексирования pandas с использованием Excel функции Filter в качестве модели для понимания процесса.
Оригинал статьи Криса здесь
Одна из первых вещей, которую изучает большинство новых пользователей pandas, - это фильтрация данных. Несмотря на то, что я работал с pandas в течение последних нескольких месяцев, недавно я понял, что у подхода к фильтрации pandas есть еще одно преимущество, которое я не использовал в повседневной работе: вы можете фильтровать по заданному набору столбцов, но обновлять другой набор столбцов, используя упрощенный синтаксис pandas. Это похоже на то, что я называю процессом "Фильтрация и редактирование" в Excel.
В этой статье будут рассмотрены некоторые примеры фильтрации DataFrame и обновления данных на основе различных критериев. Попутно я объясню еще кое-что об индексировании pandas и о том, как использовать такие методы индексирования, как .loc и .iloc, для быстрого и легкого обновления подмножества данных на основе простых или сложных критериев.
Помимо Pivot Table (сводной таблицы), одним из самых популярных инструментов в Excel является Filter. Этот простой инструмент позволяет быстро фильтровать и сортировать данные по различным числовым, текстовым критериям и критериям форматирования.
Вот снимок экрана с некоторыми образцами, отфильтрованными по нескольким критериям:

Процесс фильтрации интуитивно понятен даже начинающему пользователю Excel. Я также заметил, что люди используют эту функцию для выбора строк данных, а затем обновляют дополнительные столбцы на основе критериев строки. Пример ниже показывает, что я имею в виду:
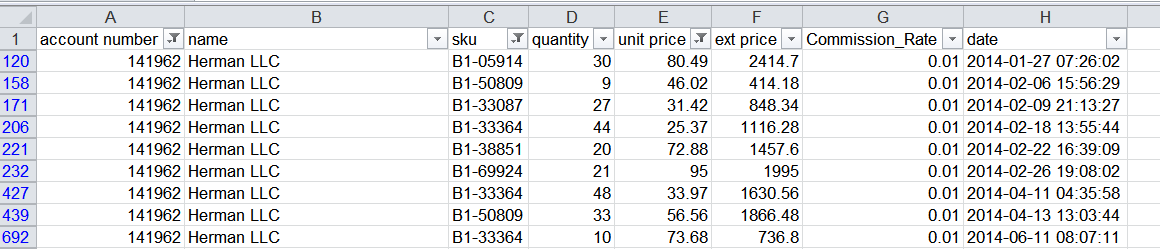
В этом примере я отфильтровал данные по Account Number (номеру счета), SKU (артикулу) и Unit Price (цене за единицу). Затем я вручную добавил столбец Commission_Rate и ввел 0.01 в каждую ячейку. Преимущество этого подхода заключается в том, что его легко понять и он может помочь управлять относительно сложными данными без написания длинных формул Excel или использования VBA. Обратной стороной этого подхода является то, что он не воспроизводится, и извне может быть сложно понять, какие критерии использовались для фильтра.
Например, если вы посмотрите на скриншот, нет очевидного способа узнать, что отфильтровано, не глядя на каждый столбец. К счастью, мы можем сделать нечто очень похожее в pandas.
Теперь, когда вы понимаете проблему, я хочу подробно рассказать о логической индексации (boolean indexing) в pandas. Это важная концепция, которую нужно понять, если вы хотите разобраться с индексированием и выбором данных в pandas. Эта идея может показаться сложной для начинающего пользователя (и, возможно, слишком простой для опытных), но я думаю, важно потратить некоторое время на ее понимание. Если вы усвоите эту концепцию, то основной процесс работы с данными в pandas упростится.
Pandas поддерживает индексацию (или выбор данных) с помощью меток (labels), целых чисел на основе позиции или списка логических значений (True/False). Использование списка логических значений для выбора строки называется логическим индексированием (boolean indexing), и ему будет уделено внимание в остальной части этой статьи.
Я обнаружил, что мой рабочий процесс, как правило, сосредоточен на использовании списков логических значений для выбора данных. Другими словами, когда я создаю DataFrames, я стараюсь сохранить в нем индекс по умолчанию.
Логическая индексация (
boolean indexing) - это один из нескольких мощных и полезных способов выбора строк данных в pandas.
Давайте посмотрим на несколько примеров DataFrames, чтобы прояснить, что делает логический индекс в pandas.
Во-первых, создадим DataFrame из списка Python:
import pandas as pd
import collections
sales = [('account', ['Jones LLC', 'Alpha Co', 'Blue Inc', 'Mega Corp']),
('Total Sales', [150, 200, 75, 300]),
('Country', ['US', 'UK', 'US', 'US'])]
# https://github.com/pandas-dev/pandas/issues/21850
df = pd.DataFrame.from_dict(collections.OrderedDict(sales))
df
| account | Total Sales | Country | |
|---|---|---|---|
| 0 | Jones LLC | 150 | US |
| 1 | Alpha Co | 200 | UK |
| 2 | Blue Inc | 75 | US |
| 3 | Mega Corp | 300 | US |
Обратите внимание, как значения 0-3 автоматически присваиваются строкам. Это индексы, и они не имеют особого значения в этом наборе данных, но полезны для pandas.
Когда мы говорим о логической индексации, то имеем в виду, что можем передать список значений из True или False, представляющих каждую строку, которую мы хотим посмотреть.
Если хотим посмотреть данные для Jones LLC, Blue Inc и Mega Corp, то список True и False будет выглядеть следующим образом:
indices = [True, False, True, True]
Неудивительно, что вы можете передать этот список в DataFrame, и он будет отображать только те строки, в которых значение равно True:
df[indices]
| account | Total Sales | Country | |
|---|---|---|---|
| 0 | Jones LLC | 150 | US |
| 2 | Blue Inc | 75 | US |
| 3 | Mega Corp | 300 | US |
Вот визуальное изображение того, что произошло:

Ручное создание списка индекса работает, но, очевидно, не масштабируется и не очень полезно для чего-либо, кроме тривиального набора данных. К счастью, pandas позволяет очень легко создавать логические индексы, используя простой язык запросов, который должен быть знаком тем, кто использовал Python (или любой другой язык в этом отношении).
Для примера рассмотрим все линии продаж из США:
df.Country == 'US'
0 True 1 False 2 True 3 True Name: Country, dtype: bool
В примере показано, как pandas возьмет вашу традиционную логику Python, применит ее к DataFrame и вернет список логических значений. Этот список логических значений затем может быть передан в DataFrame для получения соответствующих строк данных.
В реальном коде вы бы не стали выполнять этот двухэтапный процесс.
Сокращенный вызов выглядит так:
df[df["Country"] == 'US']
| account | Total Sales | Country | |
|---|---|---|---|
| 0 | Jones LLC | 150 | US |
| 2 | Blue Inc | 75 | US |
| 3 | Mega Corp | 300 | US |
Хотя эта концепция проста, но вы можете написать довольно сложную логику для фильтрации данных, используя возможности Python.
В этом примере
df[df.Country == 'US']эквивалентноdf[df["Country"] == 'US']. Обозначение.более чистое, но не будет работать, если в имени столбца присутствуют пробелы.
Теперь, когда мы выяснили, как выбирать строки данных, как мы можем контролировать, какие столбцы отображать. В приведенном выше примере нет очевидного способа сделать это. Pandas может поддерживать этот вариант, используя два типа индексации на основе местоположения: .loc и .iloc. Эти функции также позволяют нам выбирать столбцы в дополнение к выбору строк, который мы видели до сих пор.
Существует много недоразумений относительно того, когда использовать .loc или iloc. Краткое описание различий заключается в следующем:
.loc используется для индексации меток.iloc используется для целых чисел на основе позицииИтак, вопрос в том, какой из них использовать? Признаю, что я тоже несколько раз спотыкался на этом. Я обнаружил, что чаще всего использую .loc. В основном потому, что мои данные не поддаются осмысленной индексации на основе позиции (другими словами, мне редко нужен .iloc), поэтому я придерживаюсь .loc.
Честно говоря, у каждого из этих методов есть свое место и они полезны во многих ситуациях. Одна из областей, в частности, связана с иерархической индексацией (MultiIndex) DataFrames.
Теперь, когда мы рассмотрели эту тему, давайте покажем, как фильтровать DataFrame по значениям в строке и выбирать определенные столбцы для отображения.
Продолжая пример, что, если мы просто хотим показать имена учетных записей (account), которые соответствуют нашему индексу?
Используя .loc, это просто:
df.loc[[True, True, False, True], "account"]
0 Jones LLC 1 Alpha Co 3 Mega Corp Name: account, dtype: object
Если вы хотите видеть несколько столбцов, просто передайте список:
df.loc[[True, True, False, True], ["account", "Country"]]
| account | Country | |
|---|---|---|
| 0 | Jones LLC | US |
| 1 | Alpha Co | UK |
| 3 | Mega Corp | US |
Настоящая сила - это когда вы создаете более сложные запросы к своим данным. В этом случае давайте покажем все названия аккаунтов (account) и страны (Country), где продажи (Total Sales) > 200:
df.loc[df["Total Sales"] > 200, ["account", "Country"]]
| account | Country | |
|---|---|---|
| 3 | Mega Corp | US |
Этот процесс можно сравнить с фильтром Excel, который мы обсуждали выше. У вас есть дополнительное преимущество: вы также можете ограничить количество извлекаемых столбцов, а не только строк.
Все это хорошая основа, но где этот процесс действительно проявляется, так это когда вы используете аналогичный подход для обновления одного или нескольких столбцов на основе выбора строки.
В качестве простого примера давайте добавим к нашим данным столбец rate (ставка комиссионного вознаграждения):
df["rate"] = 0.02
df
| account | Total Sales | Country | rate | |
|---|---|---|---|---|
| 0 | Jones LLC | 150 | US | 0.02 |
| 1 | Alpha Co | 200 | UK | 0.02 |
| 2 | Blue Inc | 75 | US | 0.02 |
| 3 | Mega Corp | 300 | US | 0.02 |
Допустим, если вы продали более 100, ваша ставка составит 5%.
Основная задача - установить логический индекс для выбора столбцов, а затем присвоить значение столбцу rate:
df.loc[df["Total Sales"] > 100, ["rate"]] = .05
df
| account | Total Sales | Country | rate | |
|---|---|---|---|---|
| 0 | Jones LLC | 150 | US | 0.05 |
| 1 | Alpha Co | 200 | UK | 0.05 |
| 2 | Blue Inc | 75 | US | 0.02 |
| 3 | Mega Corp | 300 | US | 0.05 |
Надеюсь, если вы прочли эту статью, то теперь сможете понять, как работает этот синтаксис.
Теперь у вас есть основы подхода "Фильтр и редактирование".
В последнем разделе этот процесс будет более подробно показан в Excel и pandas.
В последнем примере мы создадим простой калькулятор комиссий, используя следующие правила.
2%.2.5%.продажа > 10 ремней (belts) за одну транзакцию получает комиссию 4%.250 долларов США плюс комиссия 4.5% для всех продаж обуви > 1000 долларов США за одну транзакцию.Чтобы сделать это в Excel, используя подход «Фильтр и редактирование»:
2%.0 долларов.2.5%.belts) и количество (quantity) > 10 и измените значение на 4%.обувь > 1000 долларов США и добавьте комиссию и бонус в размере 4.5% и 250 долларов США соответственно.Я не собираюсь показывать снимки экрана каждого шага, но вот последний фильтр:
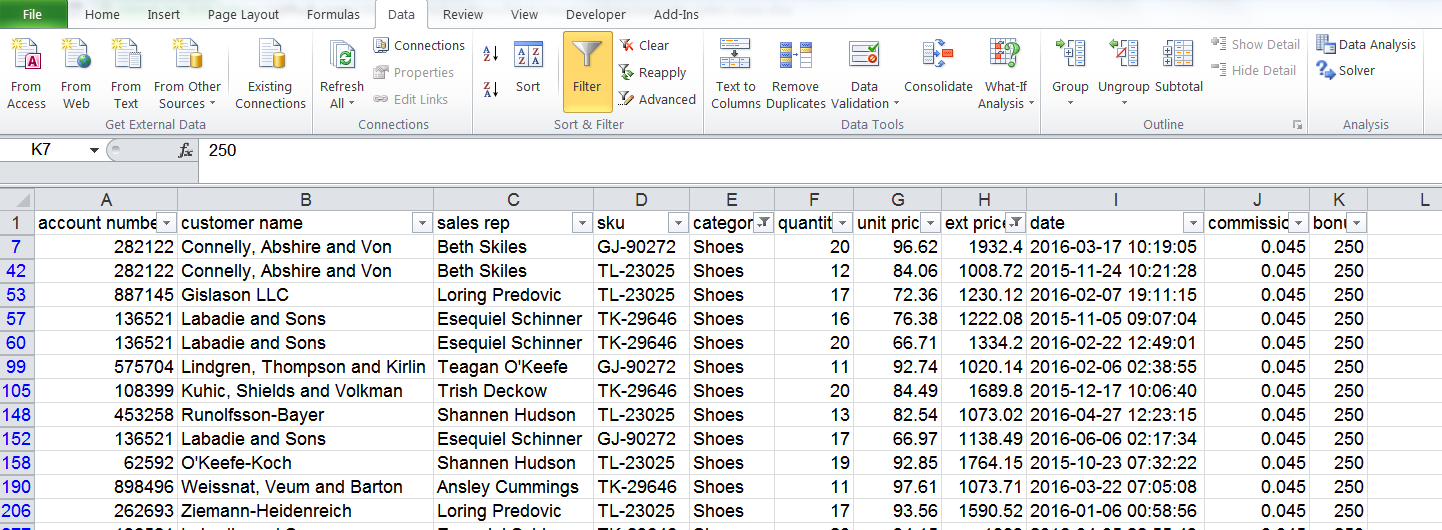
Этот подход достаточно прост для манипуляций в Excel, но его нельзя повторить и проверить. Конечно, есть и другие подходы для этого в Excel - например, формулы или VBA. Однако этот подход с фильтром и редактированием является обычным и иллюстрирует логику pandas.
Теперь давайте рассмотрим весь пример в pandas.
Сначала прочтите Excel файл и добавьте столбец со значением по умолчанию 2%:
import pandas as pd
df = pd.read_excel("https://github.com/chris1610/pbpython/blob/master/data/sample-sales-reps.xlsx?raw=true")
df["commission"] = .02
df.head()
| account number | customer name | sales rep | sku | category | quantity | unit price | ext price | date | commission | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 680916 | Mueller and Sons | Loring Predovic | GP-14407 | Belt | 19 | 88.49 | 1681.31 | 2015-11-17 05:58:34 | 0.02 |
| 1 | 680916 | Mueller and Sons | Loring Predovic | FI-01804 | Shirt | 3 | 78.07 | 234.21 | 2016-02-13 04:04:11 | 0.02 |
| 2 | 530925 | Purdy and Sons | Teagan O'Keefe | EO-54210 | Shirt | 19 | 30.21 | 573.99 | 2015-08-11 12:44:38 | 0.02 |
| 3 | 14406 | Harber, Lubowitz and Fahey | Esequiel Schinner | NZ-99565 | Shirt | 12 | 90.29 | 1083.48 | 2016-01-23 02:15:50 | 0.02 |
| 4 | 398620 | Brekke Ltd | Esequiel Schinner | NZ-99565 | Shirt | 5 | 72.64 | 363.20 | 2015-08-10 07:16:03 | 0.02 |
Следующее правило комиссии: все рубашки получают 2.5%, а продажи поясов > 10 получают ставку 4%:
df.loc[df["category"] == "Shirt", ["commission"]] = .025
df.loc[(df["category"] == "Belt") & (df["quantity"] >= 10), ["commission"]] = .04
df.head()
| account number | customer name | sales rep | sku | category | quantity | unit price | ext price | date | commission | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 680916 | Mueller and Sons | Loring Predovic | GP-14407 | Belt | 19 | 88.49 | 1681.31 | 2015-11-17 05:58:34 | 0.040 |
| 1 | 680916 | Mueller and Sons | Loring Predovic | FI-01804 | Shirt | 3 | 78.07 | 234.21 | 2016-02-13 04:04:11 | 0.025 |
| 2 | 530925 | Purdy and Sons | Teagan O'Keefe | EO-54210 | Shirt | 19 | 30.21 | 573.99 | 2015-08-11 12:44:38 | 0.025 |
| 3 | 14406 | Harber, Lubowitz and Fahey | Esequiel Schinner | NZ-99565 | Shirt | 12 | 90.29 | 1083.48 | 2016-01-23 02:15:50 | 0.025 |
| 4 | 398620 | Brekke Ltd | Esequiel Schinner | NZ-99565 | Shirt | 5 | 72.64 | 363.20 | 2015-08-10 07:16:03 | 0.025 |
Последнее правило комиссии - добавить специальный бонус:
df["bonus"] = 0
df.loc[(df["category"] == "Shoes") & (df["ext price"] >= 1000 ), ["bonus", "commission"]] = (250, 0.045)
# Показать образец строк, показывающих этот бонус:
df.iloc[3:7]
| account number | customer name | sales rep | sku | category | quantity | unit price | ext price | date | commission | bonus | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | 14406 | Harber, Lubowitz and Fahey | Esequiel Schinner | NZ-99565 | Shirt | 12 | 90.29 | 1083.48 | 2016-01-23 02:15:50 | 0.025 | 0 |
| 4 | 398620 | Brekke Ltd | Esequiel Schinner | NZ-99565 | Shirt | 5 | 72.64 | 363.20 | 2015-08-10 07:16:03 | 0.025 | 0 |
| 5 | 282122 | Connelly, Abshire and Von | Beth Skiles | GJ-90272 | Shoes | 20 | 96.62 | 1932.40 | 2016-03-17 10:19:05 | 0.045 | 250 |
| 6 | 398620 | Brekke Ltd | Esequiel Schinner | DU-87462 | Shirt | 10 | 67.64 | 676.40 | 2015-11-25 22:05:36 | 0.025 | 0 |
Для расчета комиссионных:
# Рассчитайте компенсацию для каждой строки
df["comp"] = df["commission"] * df["ext price"] + df["bonus"]
# Подведите итоги и округлите результаты по торговым представителям
df.groupby(["sales rep"])["comp"].sum().round(2)
sales rep Ansley Cummings 2169.76 Beth Skiles 3028.60 Esequiel Schinner 10451.21 Loring Predovic 10108.60 Shannen Hudson 5275.66 Teagan O'Keefe 7989.52 Trish Deckow 5807.74 Name: comp, dtype: float64
Спасибо, что прочитали статью. Я считаю, что одна из самых больших проблем для новых пользователей в изучении того, как использовать pandas, - это выяснить, как использовать свои знания на основе Excel для создания эквивалентного решения на основе pandas. Во многих случаях решение pandas будет более надежным, быстрым, легким для аудита и более мощным. Однако процесс обучения может занять некоторое время. Я надеюсь, что этот пример, показывающий, как решить проблему с помощью инструмента "Фильтр" в Excel, станет полезным руководством для тех, кто только начинает свое pandas путешествие. Удачи!
Подписка на онлайн-обучение