Цель этой статьи - показать ряд повседневных задач Excel и то, как они выполняются в pandas. Некоторые примеры тривиальны, но я думаю, важно представить как простые, так и более сложные функции.
В качестве дополнительного бонуса я собираюсь выполнить нечеткое сопоставление строк (fuzzy string matching), чтобы продемонстрировать, как pandas могут использовать модули Python.
оригинал статьи Криса тут
Разберемся? Давайте начнем.
Первая задача, которую я покажу, - это суммирование нескольких столбцов для добавления итогового столбца.
Начнем с импорта данных из Excel в кадр данных pandas:
import pandas as pd
import numpy as np
df = pd.read_excel("https://github.com/dm-fedorov/pandas_basic/blob/master/%D0%B1%D1%8B%D1%81%D1%82%D1%80%D0%BE%D0%B5%20%D0%B2%D0%B2%D0%B5%D0%B4%D0%B5%D0%BD%D0%B8%D0%B5%20%D0%B2%20pandas/data/excel-comp-data.xlsx?raw=True")
df.head()
| account | name | street | city | state | postal-code | Jan | Feb | Mar | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 211829 | Kerluke, Koepp and Hilpert | 34456 Sean Highway | New Jaycob | Texas | 28752 | 10000 | 62000 | 35000 |
| 1 | 320563 | Walter-Trantow | 1311 Alvis Tunnel | Port Khadijah | NorthCarolina | 38365 | 95000 | 45000 | 35000 |
| 2 | 648336 | Bashirian, Kunde and Price | 62184 Schamberger Underpass Apt. 231 | New Lilianland | Iowa | 76517 | 91000 | 120000 | 35000 |
| 3 | 109996 | D'Amore, Gleichner and Bode | 155 Fadel Crescent Apt. 144 | Hyattburgh | Maine | 46021 | 45000 | 120000 | 10000 |
| 4 | 121213 | Bauch-Goldner | 7274 Marissa Common | Shanahanchester | California | 49681 | 162000 | 120000 | 35000 |
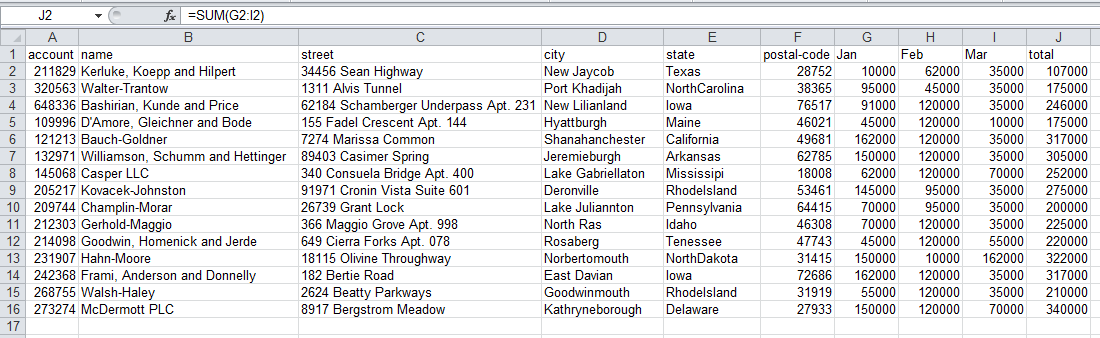
Мы хотим добавить столбец с итогами, чтобы показать общие продажи за январь, февраль и март. Это просто сделать в Excel и в pandas.
Для Excel я добавил формулу SUM(G2:I2) в столбец J.
Вот как это выглядит:
Далее, вот как это делается в pandas:
df["total"] = df["Jan"] + df["Feb"] + df["Mar"]
df.head()
| account | name | street | city | state | postal-code | Jan | Feb | Mar | total | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 211829 | Kerluke, Koepp and Hilpert | 34456 Sean Highway | New Jaycob | Texas | 28752 | 10000 | 62000 | 35000 | 107000 |
| 1 | 320563 | Walter-Trantow | 1311 Alvis Tunnel | Port Khadijah | NorthCarolina | 38365 | 95000 | 45000 | 35000 | 175000 |
| 2 | 648336 | Bashirian, Kunde and Price | 62184 Schamberger Underpass Apt. 231 | New Lilianland | Iowa | 76517 | 91000 | 120000 | 35000 | 246000 |
| 3 | 109996 | D'Amore, Gleichner and Bode | 155 Fadel Crescent Apt. 144 | Hyattburgh | Maine | 46021 | 45000 | 120000 | 10000 | 175000 |
| 4 | 121213 | Bauch-Goldner | 7274 Marissa Common | Shanahanchester | California | 49681 | 162000 | 120000 | 35000 | 317000 |
Затем получим итоговые и некоторые другие значения за каждый месяц.
Пытаемся сделать в Excel:
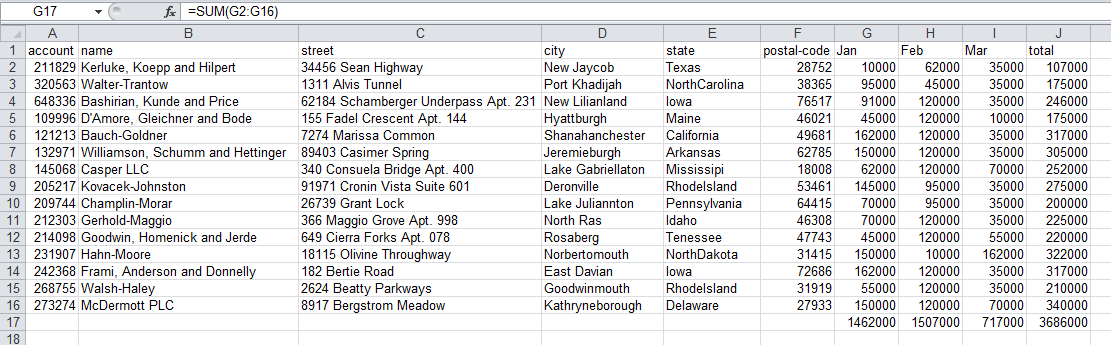
Как видите, мы добавили SUM(G2:G16) в строку 17 в каждом столбце, чтобы получить итоги по месяцам.
В pandas легко выполнять анализ на уровне столбцов. Вот пара примеров:
df["Jan"].sum(), df["Jan"].mean(), df["Jan"].min(), df["Jan"].max()
(1462000, 97466.66666666667, 10000, 162000)
Теперь хотим в pandas сложить сумму по месяцам с итогом (total).
Здесь pandas и Excel немного расходятся. В Excel очень просто складывать итоги в ячейках за каждый месяц.
Поскольку pandas необходимо поддерживать целостность всего DataFrame, то придется добавить еще пару шагов.
Сначала создайте сумму для столбцов по месяцам и итога (total).
sum_row = df[["Jan", "Feb", "Mar", "total"]].sum()
sum_row
Jan 1462000 Feb 1507000 Mar 717000 total 3686000 dtype: int64
Интуитивно понятно, если вы хотите добавить итоги в виде строки, то нужно проделать некоторые незначительные манипуляции.
Для начала - транспонировать данные и преобразовать Series в DataFrame, чтобы было проще объединить существующие данные.
Атрибут T позволяет преобразовать данные из строк в столбцы.
df_sum = pd.DataFrame(data=sum_row).T
df_sum
| Jan | Feb | Mar | total | |
|---|---|---|---|---|
| 0 | 1462000 | 1507000 | 717000 | 3686000 |
Последнее, что нужно сделать перед суммированием итогов, - это добавить недостающие столбцы.
Для этого используем функцию reindex.
Хитрость заключается в том, чтобы добавить все наши столбцы, а затем разрешить pandas заполнить отсутствующие значения.
df_sum = df_sum.reindex(columns=df.columns)
df_sum
| account | name | street | city | state | postal-code | Jan | Feb | Mar | total | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NaN | NaN | NaN | NaN | NaN | NaN | 1462000 | 1507000 | 717000 | 3686000 |
Теперь, когда у нас есть красиво отформатированный DataFrame, можем добавить его к существующему, используя метод append:
df_final = df.append(df_sum, ignore_index=True)
df_final.tail(3)
| account | name | street | city | state | postal-code | Jan | Feb | Mar | total | |
|---|---|---|---|---|---|---|---|---|---|---|
| 13 | 268755.0 | Walsh-Haley | 2624 Beatty Parkways | Goodwinmouth | RhodeIsland | 31919.0 | 55000 | 120000 | 35000 | 210000 |
| 14 | 273274.0 | McDermott PLC | 8917 Bergstrom Meadow | Kathryneborough | Delaware | 27933.0 | 150000 | 120000 | 70000 | 340000 |
| 15 | NaN | NaN | NaN | NaN | NaN | NaN | 1462000 | 1507000 | 717000 | 3686000 |
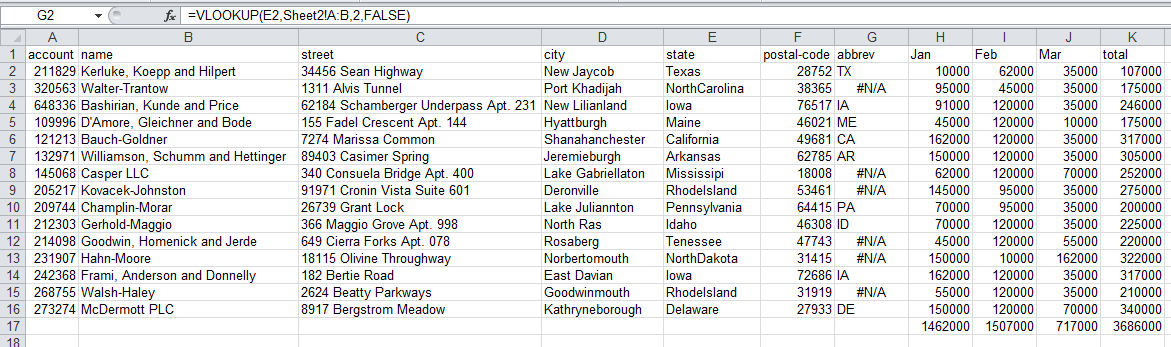
Вы заметите, что после выполнения vlookup ряд значений отображаются неправильно. Это потому, что мы неправильно написали некоторые штаты. Обработать это в Excel для больших наборов данных сложно.
В pandas у нас есть вся мощь экосистемы Python. Размышляя о том, как решить эту проблему с грязными данными, я подумал о попытке сопоставления нечеткого текста (fuzzy text matching), чтобы определить правильное значение.
К счастью, кто-то проделал большую работу в этом направлении.
В библиотеке fuzzy wuzzy есть несколько довольно полезных функций для таких ситуаций.
fuzzywuzzy использует расстояние Левенштейна для вычисления различий между последовательностями.
см. Применение библиотеки FuzzyWuzzy для нечёткого сравнения в Python на Хабре
#!pip3 install fuzzywuzzy
#!pip install python-Levenshtein
Начнем с импорта соответствующих нечетких функций:
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
Другой фрагмент кода, который нам нужен, - это отображение имени штата в аббревиатуру. Вместо того, чтобы пытаться напечатать его самостоятельно, небольшой поиск в Google подсказал следующий код:
state_to_code = {"VERMONT": "VT", "GEORGIA": "GA", "IOWA": "IA", "Armed Forces Pacific": "AP", "GUAM": "GU",
"KANSAS": "KS", "FLORIDA": "FL", "AMERICAN SAMOA": "AS", "NORTH CAROLINA": "NC", "HAWAII": "HI",
"NEW YORK": "NY", "CALIFORNIA": "CA", "ALABAMA": "AL", "IDAHO": "ID", "FEDERATED STATES OF MICRONESIA": "FM",
"Armed Forces Americas": "AA", "DELAWARE": "DE", "ALASKA": "AK", "ILLINOIS": "IL",
"Armed Forces Africa": "AE", "SOUTH DAKOTA": "SD", "CONNECTICUT": "CT", "MONTANA": "MT", "MASSACHUSETTS": "MA",
"PUERTO RICO": "PR", "Armed Forces Canada": "AE", "NEW HAMPSHIRE": "NH", "MARYLAND": "MD", "NEW MEXICO": "NM",
"MISSISSIPPI": "MS", "TENNESSEE": "TN", "PALAU": "PW", "COLORADO": "CO", "Armed Forces Middle East": "AE",
"NEW JERSEY": "NJ", "UTAH": "UT", "MICHIGAN": "MI", "WEST VIRGINIA": "WV", "WASHINGTON": "WA",
"MINNESOTA": "MN", "OREGON": "OR", "VIRGINIA": "VA", "VIRGIN ISLANDS": "VI", "MARSHALL ISLANDS": "MH",
"WYOMING": "WY", "OHIO": "OH", "SOUTH CAROLINA": "SC", "INDIANA": "IN", "NEVADA": "NV", "LOUISIANA": "LA",
"NORTHERN MARIANA ISLANDS": "MP", "NEBRASKA": "NE", "ARIZONA": "AZ", "WISCONSIN": "WI", "NORTH DAKOTA": "ND",
"Armed Forces Europe": "AE", "PENNSYLVANIA": "PA", "OKLAHOMA": "OK", "KENTUCKY": "KY", "RHODE ISLAND": "RI",
"DISTRICT OF COLUMBIA": "DC", "ARKANSAS": "AR", "MISSOURI": "MO", "TEXAS": "TX", "MAINE": "ME"}
Вот несколько примеров того, как работает функция сопоставления нечеткого текста:
process.extractOne("Minnesotta", choices=state_to_code.keys())
# ('результат', индекс сходства)
('MINNESOTA', 95)
process.extractOne("AlaBAMMazzz", choices=state_to_code.keys(), score_cutoff=80)
Теперь, когда мы знаем, как это работает, создаем функцию, которая берет столбец штата и преобразует его в допустимое сокращение.
Для этих данных используем порог наилучшего результата совпадения score_cutoff=80. Можете поиграть с этим значением, чтобы увидеть, какое число подходит для ваших данных.
В функции мы либо возвращаем допустимое сокращение, либо np.nan, чтобы у нас были допустимые значения в поле.
def convert_state(row):
if pd.notnull(row['state']):
abbrev = process.extractOne(row["state"], choices=state_to_code.keys(), score_cutoff=80)
if abbrev:
return state_to_code[abbrev[0]]
return np.nan
Добавьте столбец в нужном месте и заполните его значениями NaN:
df_final.insert(6, "abbrev", np.nan)
df_final.head()
| account | name | street | city | state | postal-code | abbrev | Jan | Feb | Mar | total | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 211829.0 | Kerluke, Koepp and Hilpert | 34456 Sean Highway | New Jaycob | Texas | 28752.0 | NaN | 10000 | 62000 | 35000 | 107000 |
| 1 | 320563.0 | Walter-Trantow | 1311 Alvis Tunnel | Port Khadijah | NorthCarolina | 38365.0 | NaN | 95000 | 45000 | 35000 | 175000 |
| 2 | 648336.0 | Bashirian, Kunde and Price | 62184 Schamberger Underpass Apt. 231 | New Lilianland | Iowa | 76517.0 | NaN | 91000 | 120000 | 35000 | 246000 |
| 3 | 109996.0 | D'Amore, Gleichner and Bode | 155 Fadel Crescent Apt. 144 | Hyattburgh | Maine | 46021.0 | NaN | 45000 | 120000 | 10000 | 175000 |
| 4 | 121213.0 | Bauch-Goldner | 7274 Marissa Common | Shanahanchester | California | 49681.0 | NaN | 162000 | 120000 | 35000 | 317000 |
Теперь используем apply для добавления сокращений в столбец abbrev:
df_final['abbrev'] = df_final.apply(convert_state, axis=1)
df_final.tail()
| account | name | street | city | state | postal-code | abbrev | Jan | Feb | Mar | total | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 11 | 231907.0 | Hahn-Moore | 18115 Olivine Throughway | Norbertomouth | NorthDakota | 31415.0 | ND | 150000 | 10000 | 162000 | 322000 |
| 12 | 242368.0 | Frami, Anderson and Donnelly | 182 Bertie Road | East Davian | Iowa | 72686.0 | IA | 162000 | 120000 | 35000 | 317000 |
| 13 | 268755.0 | Walsh-Haley | 2624 Beatty Parkways | Goodwinmouth | RhodeIsland | 31919.0 | RI | 55000 | 120000 | 35000 | 210000 |
| 14 | 273274.0 | McDermott PLC | 8917 Bergstrom Meadow | Kathryneborough | Delaware | 27933.0 | DE | 150000 | 120000 | 70000 | 340000 |
| 15 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 1462000 | 1507000 | 717000 | 3686000 |
Думаю, это круто!
Мы разработали очень простой процесс для очистки данных. Очевидно, когда у вас 15 строк, это не имеет большого значения. Однако что, если бы у вас было 15 000?
В последнем разделе этой статьи давайте рассмотрим промежуточные итоги (subtotal) по штатам.
В Excel мы бы использовали инструмент subtotal:
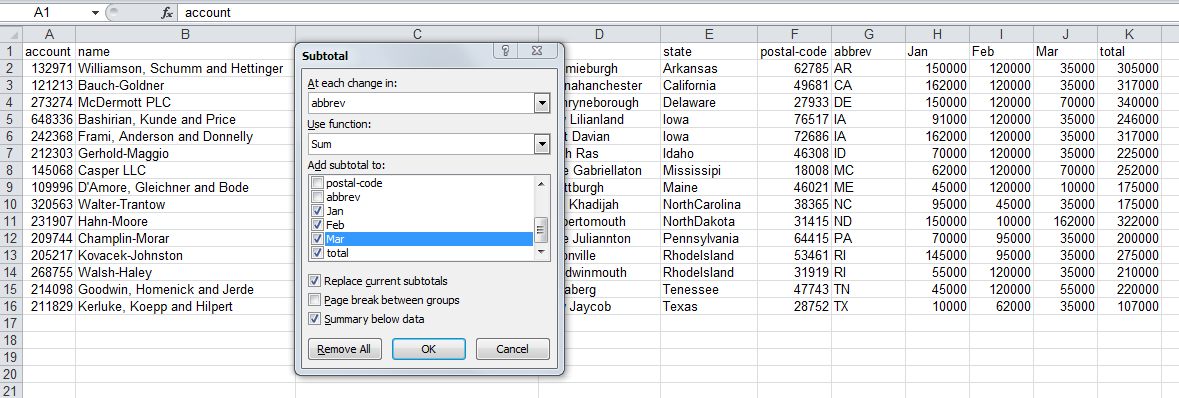
Результат будет выглядеть так:
Создание промежуточного итога в pandas выполняется с помощью метода groupby:
df_sub = df_final[["abbrev", "Jan", "Feb", "Mar", "total"]].groupby('abbrev').sum()
df_sub
| Jan | Feb | Mar | total | |
|---|---|---|---|---|
| abbrev | ||||
| AR | 150000 | 120000 | 35000 | 305000 |
| CA | 162000 | 120000 | 35000 | 317000 |
| DE | 150000 | 120000 | 70000 | 340000 |
| IA | 253000 | 240000 | 70000 | 563000 |
| ID | 70000 | 120000 | 35000 | 225000 |
| ME | 45000 | 120000 | 10000 | 175000 |
| MS | 62000 | 120000 | 70000 | 252000 |
| NC | 95000 | 45000 | 35000 | 175000 |
| ND | 150000 | 10000 | 162000 | 322000 |
| PA | 70000 | 95000 | 35000 | 200000 |
| RI | 200000 | 215000 | 70000 | 485000 |
| TN | 45000 | 120000 | 55000 | 220000 |
| TX | 10000 | 62000 | 35000 | 107000 |
Затем хотим отобразить данные с обозначением валюты, используя applymap для всех значений в кадре данных:
def money(x):
return "${:,.0f}".format(x)
formatted_df = df_sub.applymap(money)
formatted_df
| Jan | Feb | Mar | total | |
|---|---|---|---|---|
| abbrev | ||||
| AR | $150,000 | $120,000 | $35,000 | $305,000 |
| CA | $162,000 | $120,000 | $35,000 | $317,000 |
| DE | $150,000 | $120,000 | $70,000 | $340,000 |
| IA | $253,000 | $240,000 | $70,000 | $563,000 |
| ID | $70,000 | $120,000 | $35,000 | $225,000 |
| ME | $45,000 | $120,000 | $10,000 | $175,000 |
| MS | $62,000 | $120,000 | $70,000 | $252,000 |
| NC | $95,000 | $45,000 | $35,000 | $175,000 |
| ND | $150,000 | $10,000 | $162,000 | $322,000 |
| PA | $70,000 | $95,000 | $35,000 | $200,000 |
| RI | $200,000 | $215,000 | $70,000 | $485,000 |
| TN | $45,000 | $120,000 | $55,000 | $220,000 |
| TX | $10,000 | $62,000 | $35,000 | $107,000 |
Форматирование выглядит неплохо, теперь можем получить итоговые значения, как раньше:
sum_row = df_sub[["Jan", "Feb", "Mar", "total"]].sum()
sum_row
Jan 1462000 Feb 1507000 Mar 717000 total 3686000 dtype: int64
Преобразуйте значения в столбцы и отформатируйте их:
df_sub_sum = pd.DataFrame(data=sum_row).T
df_sub_sum = df_sub_sum.applymap(money)
df_sub_sum
| Jan | Feb | Mar | total | |
|---|---|---|---|---|
| 0 | $1,462,000 | $1,507,000 | $717,000 | $3,686,000 |
Наконец, добавьте итоговое значение в DataFrame:
final_table = formatted_df.append(df_sub_sum)
final_table
| Jan | Feb | Mar | total | |
|---|---|---|---|---|
| AR | $150,000 | $120,000 | $35,000 | $305,000 |
| CA | $162,000 | $120,000 | $35,000 | $317,000 |
| DE | $150,000 | $120,000 | $70,000 | $340,000 |
| IA | $253,000 | $240,000 | $70,000 | $563,000 |
| ID | $70,000 | $120,000 | $35,000 | $225,000 |
| ME | $45,000 | $120,000 | $10,000 | $175,000 |
| MS | $62,000 | $120,000 | $70,000 | $252,000 |
| NC | $95,000 | $45,000 | $35,000 | $175,000 |
| ND | $150,000 | $10,000 | $162,000 | $322,000 |
| PA | $70,000 | $95,000 | $35,000 | $200,000 |
| RI | $200,000 | $215,000 | $70,000 | $485,000 |
| TN | $45,000 | $120,000 | $55,000 | $220,000 |
| TX | $10,000 | $62,000 | $35,000 | $107,000 |
| 0 | $1,462,000 | $1,507,000 | $717,000 | $3,686,000 |
Вы заметите, что для итоговой строки индекс равен 0.
Можем изменить это с помощью метода rename:
final_table = final_table.rename(index={0:"Total"})
final_table
| Jan | Feb | Mar | total | |
|---|---|---|---|---|
| AR | $150,000 | $120,000 | $35,000 | $305,000 |
| CA | $162,000 | $120,000 | $35,000 | $317,000 |
| DE | $150,000 | $120,000 | $70,000 | $340,000 |
| IA | $253,000 | $240,000 | $70,000 | $563,000 |
| ID | $70,000 | $120,000 | $35,000 | $225,000 |
| ME | $45,000 | $120,000 | $10,000 | $175,000 |
| MS | $62,000 | $120,000 | $70,000 | $252,000 |
| NC | $95,000 | $45,000 | $35,000 | $175,000 |
| ND | $150,000 | $10,000 | $162,000 | $322,000 |
| PA | $70,000 | $95,000 | $35,000 | $200,000 |
| RI | $200,000 | $215,000 | $70,000 | $485,000 |
| TN | $45,000 | $120,000 | $55,000 | $220,000 |
| TX | $10,000 | $62,000 | $35,000 | $107,000 |
| Total | $1,462,000 | $1,507,000 | $717,000 | $3,686,000 |
Модуль
sidetableзначительно упрощает этот процесс и делает его более надежным.
К настоящему времени большинство людей знают, что pandas умеет выполнять множество сложных манипуляций с данными подобно Excel. Изучая pandas, я все еще пытаюсь вспомнить, как это сделать в Excel. Понимаю, что это сравнение может быть не совсем справедливым - это разные инструменты. Однако я надеюсь достучаться до людей, которые знают Excel и хотят узнать, какие существуют альтернативы для их потребностей в обработке данных. Надеюсь, эти примеры помогут почувствовать уверенность в том, что можно заменить множество бесполезных манипуляций с данными в Excel с помощью pandas.
Подписка на онлайн-обучениеВ качестве бонуса рекомендую видео Excel is Evil - Why it has no place in research