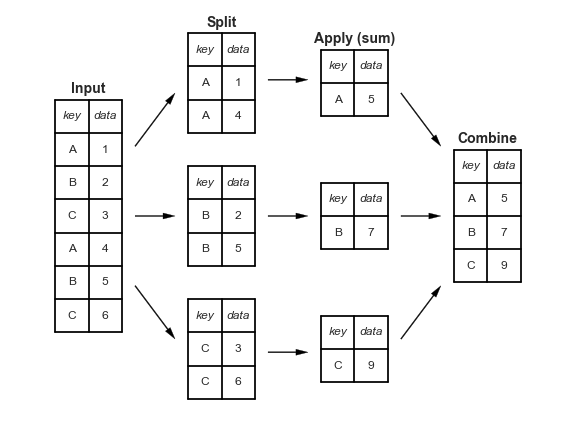
В первой части уроков мы обсудили данные, метки, кодировки и типы кодирования. Следующая важная часть API Altair - это подход к группированию и агрегированию данных.
import altair as alt
from vega_datasets import data
# загрузили набор данных про машины
cars = data.cars()
cars.head()
| Name | Miles_per_Gallon | Cylinders | Displacement | Horsepower | Weight_in_lbs | Acceleration | Year | Origin | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | chevrolet chevelle malibu | 18.0 | 8 | 307.0 | 130.0 | 3504 | 12.0 | 1970-01-01 | USA |
| 1 | buick skylark 320 | 15.0 | 8 | 350.0 | 165.0 | 3693 | 11.5 | 1970-01-01 | USA |
| 2 | plymouth satellite | 18.0 | 8 | 318.0 | 150.0 | 3436 | 11.0 | 1970-01-01 | USA |
| 3 | amc rebel sst | 16.0 | 8 | 304.0 | 150.0 | 3433 | 12.0 | 1970-01-01 | USA |
| 4 | ford torino | 17.0 | 8 | 302.0 | 140.0 | 3449 | 10.5 | 1970-01-01 | USA |
Что касается данных об автомобилях, вы можете разделить их по происхождению (Origin), вычислить среднее значение миль на галлон (miles per gallon), а затем объединить результаты.
В Pandas операция выглядит так:
cars.groupby('Origin')['Miles_per_Gallon'].mean()
Origin Europe 27.891429 Japan 30.450633 USA 20.083534 Name: Miles_per_Gallon, dtype: float64
В Altair такой вид "разделения-применения-комбинирования" (split-apply-combine) может быть выполнен путем передачи оператора агрегирования внутри строки в любую кодировку (encoding).
Например, мы можем отобразить график, представляющий вышеуказанную агрегацию, следующим образом:
alt.Chart(cars).mark_bar().encode(
y='Origin',
x='mean(Miles_per_Gallon)'
)
Обратите внимание, что группировка выполняется неявно внутри кодировок: здесь мы группируем только по происхождению (Origin), а затем вычисляем среднее значение по каждой группе.
Одно из наиболее распространенных применений биннинга - создание гистограмм. Например, вот гистограмма миль на галлон (miles per gallon):
alt.Chart(cars).mark_bar().encode(
alt.X('Miles_per_Gallon', bin=True),
alt.Y('count()'),
alt.Color('Origin')
)
Интересно то, что декларативный подход Altair позволяет присваивать эти значения разным кодировкам, чтобы увидеть другие представления тех же данных.
Например, если мы присвоим цвету (color) количество миль на галлон (miles per gallon), то получим следующее представление данных:
alt.Chart(cars).mark_bar().encode(
color=alt.Color('Miles_per_Gallon', bin=True),
x='count()',
y='Origin'
)
Это дает лучшее представление о доле MPG (миль на галлон) в каждой стране.
При желании мы можем нормализовать количество по оси x, чтобы напрямую сравнивать пропорции:
alt.Chart(cars).mark_bar().encode(
color=alt.Color('Miles_per_Gallon', bin=True),
x=alt.X('count()', stack='normalize'),
y='Origin'
)
Видим, что более половины автомобилей в США относятся к категории "с низким пробегом" (low mileage).
Снова изменив кодировку (encoding), давайте сопоставим цвет с количеством color='count()':
alt.Chart(cars).mark_rect().encode(
x=alt.X('Miles_per_Gallon', bin=alt.Bin(maxbins=20)),
color='count()',
y='Origin',
)
Видим набор данных, похожий на тепловую карту!
Это одна из прекрасных особенностей Altair: через грамматику API он показывает отношения между разными типами диаграмм, например, двухмерная тепловая карта кодирует те же данные, что и гистограмма с накоплением (stacked)!
Агрегаты (aggregates) также могут использоваться с данными, которые неявно объединены в группы. Например, посмотрите на этот график MPG (миль на галлон) с течением времени:
alt.Chart(cars).mark_point().encode(
x='Year:T',
color='Origin',
y='Miles_per_Gallon'
)
Тот факт, что точки пересекаются, затрудняет просмотр важных частей данных; мы можем сделать его более ясным, построив среднее значение в каждой группе (здесь среднее значение каждой комбинации Год/Страна):
alt.Chart(cars).mark_line().encode(
x='Year:T',
color='Origin',
y='mean(Miles_per_Gallon)'
)
Однако совокупное среднее значение (mean) отражает лишь часть истории: Altair также предоставляет встроенные инструменты для вычисления нижней и верхней границ доверительных интервалов для среднего.
Мы можем использовать здесь mark_area() и указать нижнюю и верхнюю границы области, используя y и y2:
alt.Chart(cars).mark_area(opacity=0.3).encode(
x='Year:T',
color='Origin',
y='ci0(Miles_per_Gallon)',
y2='ci1(Miles_per_Gallon)'
)
Одним из особых видов биннинга является группировка временных значений по аспектам даты: например, месяц года или день месяца. Чтобы изучить это, давайте посмотрим на простой набор данных, состоящий из средних температур в Сиэтле:
temps = data.seattle_temps()
temps.head()
| date | temp | |
|---|---|---|
| 0 | 2010-01-01 00:00:00 | 39.4 |
| 1 | 2010-01-01 01:00:00 | 39.2 |
| 2 | 2010-01-01 02:00:00 | 39.0 |
| 3 | 2010-01-01 03:00:00 | 38.9 |
| 4 | 2010-01-01 04:00:00 | 38.8 |
Если мы попытаемся построить график по этим данным с помощью Altair, то получим ошибку MaxRowsError:
alt.Chart(temps).mark_line().encode(
x='date:T',
y='temp:Q'
)
---------------------------------------------------------------------------
MaxRowsError Traceback (most recent call last)
len(temps)
8759
Мы решили возбудить исключение
MaxRowsErrorдля наборов данных размером более5000строк из-за наших наблюдений за учащимися, использующими Altair, потому что, если вы не задумаетесь о том, как представлены данные, то довольно легко получить очень большие Jupyter блокноты, в которых снизится производительность.
Когда вы передаете фрейм данных pandas в диаграмму Altair, то в результате данные преобразуются в JSON формат и сохраняются в спецификации диаграммы. Затем эта спецификация встраивается в выходные данные Jupyter блокнота, и если вы сделаете таким образом несколько десятков диаграмм с достаточно большим набором данных, то это может значительно замедлить работу вашей машины.
Так как же обойти эту ошибку? Есть несколько способов:
1) Используйте меньший набор данных. Например, мы могли бы использовать Pandas для суммирования дневных температур:
import pandas as pd
temps = temps.groupby(pd.DatetimeIndex(temps.date).date).mean().reset_index()
2) Отключите MaxRowsError, используя
alt.data_transformers.enable('default', max_rows=None)
Но учтите, что это может привести к очень большим Jupyter блокнотам, если вы не будете осторожны.
3) Обслуживайте свои данные с локального поточного сервера. Пакет сервера данных altair упрощает это.
alt.data_transformers.enable('data_server')
Обратите внимание, что этот подход может не работать с некоторыми облачными сервисами для Jupyter ноутбуков.
4) Используйте URL-адрес, указывающий на источник данных. Создание gist - это быстрый и простой способ хранить часто используемые данные.
temps = "https://raw.githubusercontent.com/altair-viz/vega_datasets/master/vega_datasets/_data/seattle-temps.csv"
alt.Chart(temps).mark_line().to_dict()
{'config': {'view': {'continuousWidth': 400, 'continuousHeight': 300}},
'data': {'url': 'https://raw.githubusercontent.com/altair-viz/vega_datasets/master/vega_datasets/_data/seattle-temps.csv'},
'mark': 'line',
'$schema': 'https://vega.github.io/schema/vega-lite/v4.8.1.json'}
Обратите внимание, что вместо включения всего набора данных используется только URL-адрес.
Теперь давайте попробуем еще раз с нашим графиком:
alt.Chart(temps).mark_line().encode(
x='date:T',
y='temp:Q'
)
Эти данные явно переполнены. Предположим, что мы хотим отсортировать данные по месяцам. Сделаем это с помощью TimeUnit Transform на дату:
alt.Chart(temps).mark_point().encode(
x=alt.X('month(date):T'),
y='temp:Q'
)
Станет понятнее, если мы просуммируем температуры:
alt.Chart(temps).mark_bar().encode(
x=alt.X('month(date):O'),
y='mean(temp):Q'
)
Можем разделить даты двумя разными способами, чтобы получить интересное представление данных, например:
alt.Chart(temps).mark_rect().encode(
x=alt.X('date(date):O'),
y=alt.Y('month(date):O'),
color='mean(temp):Q'
)
Или можем посмотреть на среднечасовую температуру как функцию месяца:
alt.Chart(temps).mark_rect().encode(
x=alt.X('hours(date):O'),
y=alt.Y('month(date):O'),
color='mean(temp):Q'
)
Этот вид преобразования может оказаться полезным при работе с временными данными.
Дополнительная информация о TimeUnit Transform доступна здесь
Altair предоставляет краткий API для создания многопанельных и многоуровневых диаграмм, таких как:
Мы кратко рассмотрим их далее.
import altair as alt
Наслоение (layering) позволяет размещать несколько меток (marks) на одной диаграмме. Один из распространенных примеров - создание графика с точками и линиями, представляющими одни и те же данные.
Давайте использовать данные об акциях (stocks) для этого примера:
from vega_datasets import data
stocks = data.stocks()
stocks.head()
| symbol | date | price | |
|---|---|---|---|
| 0 | MSFT | 2000-01-01 | 39.81 |
| 1 | MSFT | 2000-02-01 | 36.35 |
| 2 | MSFT | 2000-03-01 | 43.22 |
| 3 | MSFT | 2000-04-01 | 28.37 |
| 4 | MSFT | 2000-05-01 | 25.45 |
Вот простой линейный график данных по акциям:
alt.Chart(stocks).mark_line().encode(
x='date:T',
y='price:Q',
color='symbol:N'
)
А вот тот же график с кружком (circle mark):
alt.Chart(stocks).mark_circle().encode(
x='date:T',
y='price:Q',
color='symbol:N'
)
Можем наложить эти два графика вместе с помощью оператора +:
lines = alt.Chart(stocks).mark_line().encode(
x='date:T',
y='price:Q',
color='symbol:N'
)
points = alt.Chart(stocks).mark_circle().encode(
x='date:T',
y='price:Q',
color='symbol:N'
)
lines + points
Оператор + всего лишь сокращение для функции alt.layer(), которая делает то же самое:
alt.layer(lines, points)
Один из шаблонов, который мы будем часто использовать, - это создать базовую диаграмму с общими элементами и сложить две копии с одним изменением:
base = alt.Chart(stocks).encode(
x='date:T',
y='price:Q',
color='symbol:N'
)
base.mark_line() + base.mark_circle()
Так же, как мы можем накладывать диаграммы друг на друга, мы можем объединить их по горизонтали, используя alt.hconcat или, что то же самое, оператор |:
base.mark_line() | base.mark_circle()
alt.hconcat(base.mark_line(),
base.mark_circle())
Это может пригодиться для создания многопанельных представлений, например, вот набор данных iris:
iris = data.iris()
iris.head()
| sepalLength | sepalWidth | petalLength | petalWidth | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
base = alt.Chart(iris).mark_point().encode(
x='petalWidth',
y='petalLength',
color='species'
)
base | base.encode(x='sepalWidth')
Вертикальная конкатенация (vertical concatenation) очень похожа на горизонтальную, но с использованием либо функции alt.hconcat(), либо оператора &:
base & base.encode(y='sepalWidth')
Поскольку это очень распространенный шаблон для объединения диаграмм по горизонтали и вертикали при изменении одной кодировки, Altair предлагает для этого сокращение, используя оператор repeat().
import altair as alt
from vega_datasets import data
iris = data.iris()
fields = ['petalLength', 'petalWidth', 'sepalLength', 'sepalWidth']
alt.Chart(iris).mark_point().encode(
alt.X(alt.repeat("column"), type='quantitative'),
alt.Y(alt.repeat("row"), type='quantitative'),
color='species'
).properties(
width=200,
height=200
).repeat(
row=fields,
column=fields[::-1]
).interactive()
Этот API все еще не так оптимизирован, как мог бы, но мы будем над этим работать.
читать далее Часть 3
Подписка на онлайн-обучение