Одна из базовых функций анализа данных - группировка и агрегирование. В некоторых случаях этого уровня анализа может быть достаточно, чтобы ответить на вопросы бизнеса. В других случаях - это может стать первым шагом в более сложном анализе.
В pandas функцию groupby можно комбинировать с одной или несколькими функциями агрегирования, чтобы быстро и легко обобщать данные. Эта концепция обманчиво проста и большинство новых пользователей pandas поймут ее. Однако они удивятся тому, насколько полезными могут стать функции агрегирования для проведения сложного анализа данных.
В этом Блокноте кратко изложены основные функции агрегирования pandas и показаны примеры более сложных настраиваемых агрегаций. Независимо от того, являетесь ли вы начинающим или опытным пользователем pandas, я думаю, вы узнаете что-то новое для себя.
Оригниал статьи Криса тут.
В контексте даннной статьи функция агрегирования - это функция, которая принимает несколько отдельных значений и возвращает сводные данные. В большинстве случаев возвращаемые данные представляют собой одно значение.
Наиболее распространенные функции агрегирования - это простое среднее (simple average) или суммирование (summation) значений.
Далее представлен пример расчета суммарной и средней стоимости билетов для набора данных "Титаник", загруженного из пакета seaborn.
15 апреля 1912 года самый большой пассажирский лайнер в истории во время своего первого рейса столкнулся с айсбергом. Когда Титаник затонул, погибли 1502 из 2224 пассажиров и членов экипажа. Эта сенсационная трагедия потрясла международное сообщество и привела к улучшению правил безопасности для судов. Одна из причин, по которой кораблекрушение привело к гибели людей, заключалась в том, что не хватало спасательных шлюпок для пассажиров и экипажа. Несмотря на то, что в выживании после затопления была определенная доля удачи, некоторые группы людей имели больше шансов выжить, чем другие.
import pandas as pd
import seaborn as sns
df = sns.load_dataset('titanic')
Каждая строка набора данных представляет одного человека. Столбцы описывают различные атрибуты, включая то, выжили ли они (survived), их возраст (age), класс пассажира (pclass), пол (sex) и стоимость проезда (fare).
df.head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
df['fare'].agg(['sum', 'mean']) # сумма и среднее по столбцу стоимости билета, здесь передаем список агрегирующих функций
sum 28693.949300 mean 32.204208 Name: fare, dtype: float64
Эта простая концепция - необходимый строительный блок для более сложного анализа.
Одна из областей, которую необходимо обсудить, - это то, что существует несколько способов вызова функции агрегирования. Как показано выше, вы можете передать список функций для применения к одному или нескольким столбцам данных.
Что, если вы хотите выполнить анализ только подмножества столбцов?
Есть два других варианта агрегирования: использование словаря и именованное агрегирование (named aggregation).
Использование словаря:
df.agg({'fare': ['sum', 'mean'],
'sex' : ['count']})
| fare | sex | |
|---|---|---|
| count | NaN | 891.0 |
| mean | 32.204208 | NaN |
| sum | 28693.949300 | NaN |
Использование кортежей (именованное агрегирование):
df.agg(fare_sum=('fare', 'sum'),
fare_mean=('fare', 'mean'),
sex_count=('sex', 'count'))
| fare | sex | |
|---|---|---|
| fare_sum | 28693.949300 | NaN |
| fare_mean | 32.204208 | NaN |
| sex_count | NaN | 891.0 |
Важно знать об этих параметрах и понимать, какой из них и когда использовать.
Я предпочитаю использовать словари для агрегирования.
Подход с кортежами ограничен возможностью применять только одно агрегирование за раз к определенному столбцу. Если мне нужно переименовать столбцы, я буду использовать функцию rename после завершения агрегации. В некоторых случаях подход со списком является более рациональным. Тем не менее, я повторю, что, на мой взгляд, словарный подход обеспечивает наиболее надежный способ для большинства ситуаций.
Теперь, когда мы знаем, как использовать агрегацию, мы можем объединить это с groupby для резюмирования данных.
Наиболее распространенными встроенными функциями агрегирования являются базовые математические функции, включая сумму (sum), среднее значение (mean), медианное значение (median), минимум (minimum), максимум (maximum), стандартное отклонение (standard deviation), дисперсию (variance), среднее абсолютное отклонение (mean absolute deviation) и произведение (product).
Мы можем применить все эти функции к fare (стоимости проезда) при группировке по embark_town (городу посадки на корабль):
agg_func_math = {
'fare': ['sum', 'mean', 'median', 'min', 'max', 'std', 'var', 'mad', 'prod']
}
df.groupby(['embark_town']).agg(agg_func_math).round(2)
| fare | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| sum | mean | median | min | max | std | var | mad | prod | |
| embark_town | |||||||||
| Cherbourg | 10072.30 | 59.95 | 29.70 | 4.01 | 512.33 | 83.91 | 7041.39 | 53.02 | 6.193716e+250 |
| Queenstown | 1022.25 | 13.28 | 7.75 | 6.75 | 90.00 | 14.19 | 201.30 | 7.87 | 6.458671e+78 |
| Southampton | 17439.40 | 27.08 | 13.00 | 0.00 | 263.00 | 35.89 | 1287.95 | 21.30 | 0.000000e+00 |
Это все относительно простая математика.
Кстати, я не нашел подходящего варианта использования функции prod, которая вычисляет произведение всех значений в группе, и включил ее для полноты картины.
Еще один полезный трюк - использовать describe для одновременного выполнения нескольких встроенных агрегаторов:
agg_func_describe = {'fare': ['describe']}
df.groupby(['embark_town']).agg(agg_func_describe).round(2)
| fare | ||||||||
|---|---|---|---|---|---|---|---|---|
| describe | ||||||||
| count | mean | std | min | 25% | 50% | 75% | max | |
| embark_town | ||||||||
| Cherbourg | 168.0 | 59.95 | 83.91 | 4.01 | 13.70 | 29.70 | 78.5 | 512.33 |
| Queenstown | 77.0 | 13.28 | 14.19 | 6.75 | 7.75 | 7.75 | 15.5 | 90.00 |
| Southampton | 644.0 | 27.08 | 35.89 | 0.00 | 8.05 | 13.00 | 27.9 | 263.00 |
После базовой математики подсчет (counting) является следующим наиболее распространенным агрегированием, которое я выполняю для сгруппированных данных.
Он несколько сложнее, чем простая математика. Вот три примера подсчета:
agg_func_count = {'embark_town': ['count', 'nunique', 'size']}
df.groupby(['deck']).agg(agg_func_count) # статистика по палубам Титаника
| embark_town | |||
|---|---|---|---|
| count | nunique | size | |
| deck | |||
| A | 15 | 2 | 15 |
| B | 45 | 2 | 47 |
| C | 59 | 3 | 59 |
| D | 33 | 2 | 33 |
| E | 32 | 3 | 32 |
| F | 13 | 3 | 13 |
| G | 4 | 1 | 4 |
Главное отличие, о котором следует помнить, заключается в том, что
countне включает значенияNaN, тогда какsizeих включает. В зависимости от набора данных это различие может оказаться полезным.
Кроме того, функция nunique исключит значения NaN из уникальных счетчиков.
Продолжайте читать, чтобы увидеть пример того, как включить NaN в подсчет уникальных значений.
В следующем примере мы можем выбрать самую высокую и самую низкую стоимость билета в зависимости от города, в котором совершили посадку пассажиры Титаника.
Следует помнить один важный момент: вы должны сначала отсортировать данные, если хотите, чтобы в качестве first (первого) и last (последнего) были выбраны максимальное и минимальное значения.
agg_func_selection = {'fare': ['first', 'last']}
df.sort_values(by=['fare'], ascending=False).groupby(['embark_town']).agg(agg_func_selection)
| fare | ||
|---|---|---|
| first | last | |
| embark_town | ||
| Cherbourg | 512.3292 | 4.0125 |
| Queenstown | 90.0000 | 6.7500 |
| Southampton | 263.0000 | 0.0000 |
В приведенном выше примере я бы рекомендовал использовать max и min, но для полноты картины включил first и last. В других приложениях (например, при анализе временных рядов) вы можете выбрать значения first и last для дальнейшего анализа.
Другой подход к выбору - использовать idxmax и idxmin для выбора значения индекса, соответствующего максимальному или минимальному значениям.
agg_func_max_min = {'fare': ['idxmax', 'idxmin']}
df.groupby(['embark_town']).agg(agg_func_max_min)
| fare | ||
|---|---|---|
| idxmax | idxmin | |
| embark_town | ||
| Cherbourg | 258 | 378 |
| Queenstown | 245 | 143 |
| Southampton | 27 | 179 |
Можем проверить результаты:
df.loc[[258, 378]]
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 258 | 1 | 1 | female | 35.0 | 0 | 0 | 512.3292 | C | First | woman | False | NaN | Cherbourg | yes | True |
| 378 | 0 | 3 | male | 20.0 | 0 | 0 | 4.0125 | C | Third | man | True | NaN | Cherbourg | no | True |
Вот еще один трюк, который можно использовать для просмотра строк с максимальной стоимостью проезда (fare):
df.loc[df.groupby('class')['fare'].idxmax()]
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 258 | 1 | 1 | female | 35.0 | 0 | 0 | 512.3292 | C | First | woman | False | NaN | Cherbourg | yes | True |
| 72 | 0 | 2 | male | 21.0 | 0 | 0 | 73.5000 | S | Second | man | True | NaN | Southampton | no | True |
| 159 | 0 | 3 | male | NaN | 8 | 2 | 69.5500 | S | Third | man | True | NaN | Southampton | no | False |
Приведенный выше пример - одно из тех мест, где агрегирование на основе списка является полезным.
Вот пример расчета моды (mode) и асимметрии (skew) данных для стоимости проезда.
from scipy.stats import skew, mode
agg_func_stats = {'fare': [skew, mode, pd.Series.mode]}
df.groupby(['embark_town']).agg(agg_func_stats)
| fare | |||
|---|---|---|---|
| skew | mode | mode | |
| embark_town | |||
| Cherbourg | 3.305112 | ([7.2292], [15]) | 7.2292 |
| Queenstown | 4.265111 | ([7.75], [30]) | 7.7500 |
| Southampton | 3.640276 | ([8.05], [43]) | 8.0500 |
Интересны результаты вычисления моды (mode). Функция mode из scipy.stats возвращает наиболее часто встречающееся значение, а также количество вхождений. Если вам просто нужно наиболее частое значение, то используйте pd.Series.mode.
Ключевым моментом является то, что вы можете использовать любую функцию, которую хотите, если она знает, как интерпретировать массив значений pandas и возвращает одно значение.
При работе с текстом функции подсчета будут работать должным образом. Вы также можете использовать функцию mode из scipy для текстовых данных.
Одно интересное приложение состоит в том, что если у вас небольшое количество различных значений, то можете использовать питоновскую функцию set для отображения списка уникальных значений.
Следующая краткая сводка для class (класса каюты) и deck (палубы) показывает, как данный подход можно использовать:
agg_func_text = {'deck': ['nunique', mode, set]}
df.groupby(['class']).agg(agg_func_text)
| deck | |||
|---|---|---|---|
| nunique | mode | set | |
| class | |||
| First | 5 | ([C], [59]) | {C, nan, A, B, E, D} |
| Second | 3 | ([F], [8]) | {nan, D, F, E} |
| Third | 3 | ([F], [5]) | {nan, F, E, G} |
Стандартные функции агрегирования pandas и функции из экосистемы Python удовлетворят многие ваши потребности в анализе данных. Однако вы, вероятно, захотите создать свои собственные пользовательские функции агрегирования. Есть четыре способа для создания собственных функций.
Чтобы проиллюстрировать различия, давайте вычислим 25-й процентиль данных (также называемый квантилью .25 или нижней квартилью), используя четыре подхода.
Во-первых, мы можем использовать функцию partial:
from functools import partial
q_25 = partial(pd.Series.quantile, q=0.25) # возвращает обортку над pd.Series.quantile()
q_25.__name__ = '25%' # пойдет в наименование будущего столбца
Затем мы определяем нашу собственную функцию (которая представляет собой небольшую обертку для quantile):
def percentile_25(x):
return x.quantile(.25)
Далее определяем лямбда-функцию и даем ей имя:
lambda_25 = lambda x: x.quantile(.25)
lambda_25.__name__ = 'lambda_25%'
Затем задаем встроенную (inline) лямбду и формируем словарь:
agg_func = {
'fare': [q_25, percentile_25, lambda_25, lambda x: x.quantile(.25)]
}
df.groupby(['embark_town']).agg(agg_func).round(2)
| fare | ||||
|---|---|---|---|---|
| 25% | percentile_25 | lambda_25% | <lambda_0> | |
| embark_town | ||||
| Cherbourg | 13.70 | 13.70 | 13.70 | 13.70 |
| Queenstown | 7.75 | 7.75 | 7.75 | 7.75 |
| Southampton | 8.05 | 8.05 | 8.05 | 8.05 |
Как видите, результаты одинаковые, но названия столбцов немного отличаются. Это область предпочтений программистов, но я рекомендую ознакомиться с вариантами, поскольку вы встретите большинство из них в онлайн-решениях.
Я предпочитаю использовать собственные функции или встроенные (inline) лямбды.
Как и во многих других областях программирования - это элемент стиля и предпочтений, но я рекомендую вам выбрать один или два подхода и придерживаться их для единообразия.
Как показано выше, существует несколько подходов к разработке пользовательских функций агрегирования.
В большинстве случаев функции представляют собой легкие обертки (wrappers) для встроенных функций pandas. Они нужны, т.к. нет возможности передать аргументы в агрегаты (aggregations).
Следующие примеры должны пояснить этот момент.
Если вы хотите подсчитать количество нулевых значений, вы можете использовать эту функцию:
def count_nulls(s):
return s.size - s.count()
Если вы хотите включить значения NaN в свои уникальные счетчики, вам необходимо указать параметр dropna=False у функции nunique.
def unique_nan(s):
return s.nunique(dropna=False)
Вот результат применения всех функций:
agg_func_custom_count = {
'embark_town': ['count', 'nunique', 'size', unique_nan, count_nulls, set]
}
df.groupby(['deck']).agg(agg_func_custom_count)
| embark_town | ||||||
|---|---|---|---|---|---|---|
| count | nunique | size | unique_nan | count_nulls | set | |
| deck | ||||||
| A | 15 | 2 | 15 | 2 | 0 | {Cherbourg, Southampton} |
| B | 45 | 2 | 47 | 3 | 2 | {nan, Cherbourg, Southampton} |
| C | 59 | 3 | 59 | 3 | 0 | {Cherbourg, Southampton, Queenstown} |
| D | 33 | 2 | 33 | 2 | 0 | {Cherbourg, Southampton} |
| E | 32 | 3 | 32 | 3 | 0 | {Cherbourg, Southampton, Queenstown} |
| F | 13 | 3 | 13 | 3 | 0 | {Cherbourg, Southampton, Queenstown} |
| G | 4 | 1 | 4 | 1 | 0 | {Southampton} |
Если вы хотите рассчитать 90-й процентиль, используйте quantile:
def percentile_90(x):
return x.quantile(.9)
Если вы хотите вычислить усеченное среднее (trimmed mean) значение, из которого исключен самый низкий 10-й процент, используйте функцию trim_mean из scipy:
from scipy.stats import trim_mean
def trim_mean_10(x):
return trim_mean(x, 0.1)
Если вы хотите получить наибольшее значение, независимо от порядка сортировки (см. ранее в этом Блокноте о first и last):
def largest(x):
return x.nlargest(1)
Это эквивалентно max, но я приведу еще один пример с nlargest ниже, чтобы подчеркнуть разницу.
#!pip3 install sparklines
from sparklines import sparklines
import numpy as np
def sparkline_str(x):
bins = np.histogram(x)[0]
sl = ''.join(sparklines(bins))
return sl
Вот они все вместе:
agg_func_largest = {
'fare': [percentile_90, trim_mean_10, largest, sparkline_str]
}
df.groupby(['class', 'embark_town']).agg(agg_func_largest)
| fare | |||||
|---|---|---|---|---|---|
| percentile_90 | trim_mean_10 | largest | sparkline_str | ||
| class | embark_town | ||||
| First | Cherbourg | 227.5250 | 85.408335 | 512.3292 | █▇▂▁▃▁▁▁▁▂ |
| Queenstown | 90.0000 | 90.000000 | 90.0000 | ▁▁▁▁▁█▁▁▁▁ | |
| Southampton | 152.3150 | 60.500160 | 263.0000 | ▃█▄▃▂▂▁▁▂▂ | |
| Second | Cherbourg | 41.5792 | 25.167500 | 41.5792 | █▄▁▁▄▂▄▁▄▅ |
| Queenstown | 12.3500 | 12.350000 | 12.3500 | ▁▁▁▁▁█▁▁▁▁ | |
| Southampton | 31.7500 | 18.202273 | 73.5000 | ▂█▂▅▁▂▁▁▁▁ | |
| Third | Cherbourg | 19.0229 | 10.677941 | 22.3583 | ▁█▃▂▁▄▃▁▂▂ |
| Queenstown | 24.0600 | 9.670476 | 29.1250 | █▁▁▂▁▁▁▂▁▂ | |
| Southampton | 31.2750 | 11.501469 | 69.5500 | ▁█▂▂▂▁▁▁▁▁ | |
Функции nlargest и nsmallest могут быть полезны для резюмирования данных в различных сценариях.
Следующий код показывает суммарную стоимость для 10 первых и 10 последних пассажиров:
def top_10_sum(x):
return x.nlargest(10).sum()
def bottom_10_sum(x):
return x.nsmallest(10).sum()
agg_func_top_bottom_sum = {
'fare': [top_10_sum, bottom_10_sum]
}
df.groupby('class').agg(agg_func_top_bottom_sum)
| fare | ||
|---|---|---|
| top_10_sum | bottom_10_sum | |
| class | ||
| First | 3361.2584 | 108.3709 |
| Second | 622.2376 | 42.0000 |
| Third | 656.3374 | 36.1291 |
Использование этого подхода может быть полезно для применения закона Парето к вашим собственным данным.
Если у вас есть сценарий, в котором небходимо запустить несколько агрегаций по столбцам, то вы можете использовать groupby в сочетании с apply, как описано в этом ответе на stack overflow.
Используя этот метод, вы получите доступ ко всем столбцам данных и сможете выбрать подходящий способ агрегирования для создания итогового DataFrame (включая наименование столбцов):
def summary(x):
result = {
'fare_sum': x['fare'].sum(),
'fare_mean': x['fare'].mean(),
'fare_range': x['fare'].max() - x['fare'].min()
}
return pd.Series(result).round(0)
df.groupby(['class']).apply(summary)
| fare_sum | fare_mean | fare_range | |
|---|---|---|---|
| class | |||
| First | 18177.0 | 84.0 | 512.0 |
| Second | 3802.0 | 21.0 | 74.0 |
| Third | 6715.0 | 14.0 | 70.0 |
Использование apply с groupby дает максимальную гибкость. Однако есть и обратная сторона. Функция apply работает медленно, поэтому этот подход следует использовать с осторожностью.
После группировки и агрегирования данных вы можете выполнять дополнительные вычисления для сгруппированных объектов.
В следующем примере определим, какой процент от общего количества проданных билетов можно отнести к каждой комбинации embark_town и class.
Мы используем метод assign() и лямбда-функцию для добавления столбца pct_total:
df.groupby(['embark_town', 'class']).agg({'fare': 'sum'}).assign(pct_total=lambda x: x / x.sum())
| fare | pct_total | ||
|---|---|---|---|
| embark_town | class | ||
| Cherbourg | First | 8901.0750 | 0.311947 |
| Second | 431.0917 | 0.015108 | |
| Third | 740.1295 | 0.025939 | |
| Queenstown | First | 180.0000 | 0.006308 |
| Second | 37.0500 | 0.001298 | |
| Third | 805.2043 | 0.028219 | |
| Southampton | First | 8936.3375 | 0.313183 |
| Second | 3333.7000 | 0.116833 | |
| Third | 5169.3613 | 0.181165 |
Следует отметить, что можно сделать проще с использованием кросс-таблицы pd.crosstab, как описано в статье:
pd.crosstab(df['embark_town'],
df['class'],
values=df['fare'],
aggfunc='sum',
normalize=True)
| class | First | Second | Third |
|---|---|---|---|
| embark_town | |||
| Cherbourg | 0.311947 | 0.015108 | 0.025939 |
| Queenstown | 0.006308 | 0.001298 | 0.028219 |
| Southampton | 0.313183 | 0.116833 | 0.181165 |
Пока мы говорим о crosstab (кросс-таблицах), полезно иметь в виду, что функции агрегации также можно комбинировать со сводными таблицами (pivot tables).
Вот небольшой пример:
pd.pivot_table(data=df,
index=['embark_town'],
columns=['class'],
aggfunc=agg_func_top_bottom_sum)
| fare | ||||||
|---|---|---|---|---|---|---|
| bottom_10_sum | top_10_sum | |||||
| class | First | Second | Third | First | Second | Third |
| embark_town | ||||||
| Cherbourg | 282.9957 | 172.2041 | 68.2500 | 3239.3542 | 334.6084 | 196.7457 |
| Queenstown | 180.0000 | 37.0500 | 73.5916 | 180.0000 | 37.0500 | 264.5750 |
| Southampton | 108.3709 | 42.0000 | 39.6291 | 2237.5251 | 614.5000 | 656.3374 |
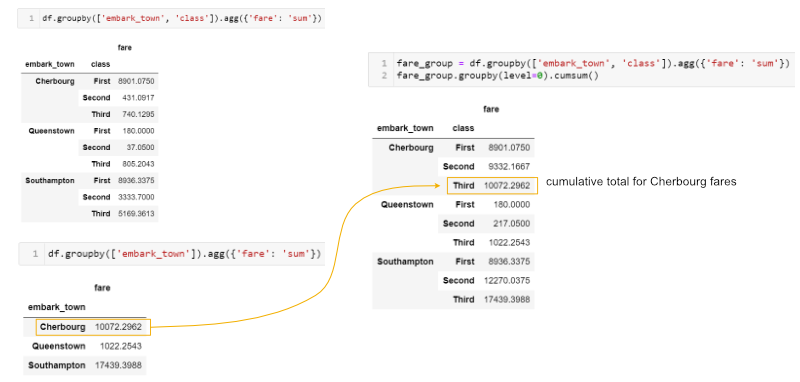
Иногда необходимо выполнить множество группировок (multiple groupby), чтобы ответить на вопрос. Например, если мы хотим увидеть кумулятивную сумму стоимости билетов, мы можем сгруппировать и агрегировать по городу (town) и классу (class), затем сгруппировать полученный объект и вычислить кумулятивную сумму (cumulative sum):
fare_group = df.groupby(['embark_town', 'class']).agg({'fare': 'sum'})
fare_group
| fare | ||
|---|---|---|
| embark_town | class | |
| Cherbourg | First | 8901.0750 |
| Second | 431.0917 | |
| Third | 740.1295 | |
| Queenstown | First | 180.0000 |
| Second | 37.0500 | |
| Third | 805.2043 | |
| Southampton | First | 8936.3375 |
| Second | 3333.7000 | |
| Third | 5169.3613 |
fare_group.groupby(level=0).cumsum()
| fare | ||
|---|---|---|
| embark_town | class | |
| Cherbourg | First | 8901.0750 |
| Second | 9332.1667 | |
| Third | 10072.2962 | |
| Queenstown | First | 180.0000 |
| Second | 217.0500 | |
| Third | 1022.2543 | |
| Southampton | First | 8936.3375 |
| Second | 12270.0375 | |
| Third | 17439.3988 |
Это может быть сложным для понимания. Вот краткое пояснение того, что мы делаем:
В следующем примере резюмируем ежедневные данные о продажах и преобразуем их в совокупное ежедневное и ежеквартальное представление.
Обратитесь к статье о Grouper, если вы не знакомы с использованием метода pd.Grouper().
В этом примере мы хотим включить сумму ежедневных продаж, а также совокупную (cumulative) сумму за квартал:
sales = pd.read_excel('https://github.com/chris1610/pbpython/blob/master/data/2018_Sales_Total_v2.xlsx?raw=True')
sales.head()
| account number | name | sku | quantity | unit price | ext price | date | |
|---|---|---|---|---|---|---|---|
| 0 | 740150 | Barton LLC | B1-20000 | 39 | 86.69 | 3380.91 | 2018-01-01 07:21:51 |
| 1 | 714466 | Trantow-Barrows | S2-77896 | -1 | 63.16 | -63.16 | 2018-01-01 10:00:47 |
| 2 | 218895 | Kulas Inc | B1-69924 | 23 | 90.70 | 2086.10 | 2018-01-01 13:24:58 |
| 3 | 307599 | Kassulke, Ondricka and Metz | S1-65481 | 41 | 21.05 | 863.05 | 2018-01-01 15:05:22 |
| 4 | 412290 | Jerde-Hilpert | S2-34077 | 6 | 83.21 | 499.26 | 2018-01-01 23:26:55 |
daily_sales = sales.groupby([pd.Grouper(key='date', freq='D')]).agg(daily_sales=('ext price', 'sum')).reset_index()
daily_sales.head()
| date | daily_sales | |
|---|---|---|
| 0 | 2018-01-01 | 6766.16 |
| 1 | 2018-01-02 | 1551.91 |
| 2 | 2018-01-03 | 4278.96 |
| 3 | 2018-01-04 | 6044.10 |
| 4 | 2018-01-05 | 1971.94 |
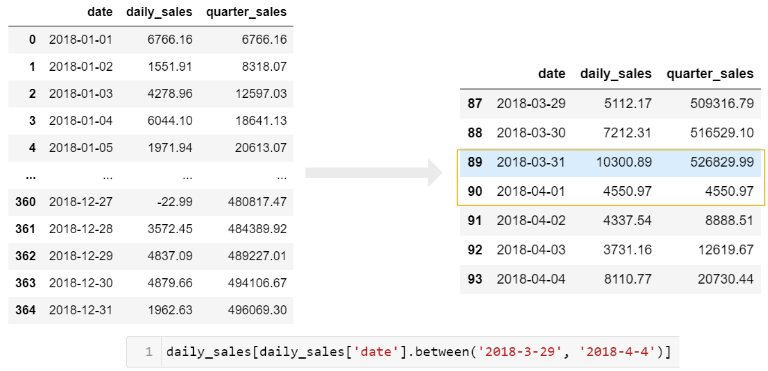
daily_sales['quarter_sales'] = daily_sales.groupby(pd.Grouper(key='date', freq='Q')).agg({'daily_sales': 'cumsum'})
daily_sales.head()
| date | daily_sales | quarter_sales | |
|---|---|---|---|
| 0 | 2018-01-01 | 6766.16 | 6766.16 |
| 1 | 2018-01-02 | 1551.91 | 8318.07 |
| 2 | 2018-01-03 | 4278.96 | 12597.03 |
| 3 | 2018-01-04 | 6044.10 | 18641.13 |
| 4 | 2018-01-05 | 1971.94 | 20613.07 |
Чтобы получить хорошее представление о том, что происходит, вам нужно взглянуть на границу квартала (с конца марта по начало апреля):
Если вы хотите просто получить совокупный (cumulative) квартальный итог, вы можете связать несколько функций groupby.
Сначала сгруппируйте ежедневные результаты, затем сгруппируйте эти результаты по кварталам и используйте кумулятивную сумму:
# веселый пример :)
sales.groupby(
[pd.Grouper(key='date',
freq='D')]).agg(
daily_sales=('ext price',
'sum')).groupby(
pd.Grouper(freq='Q')).agg(
{'daily_sales': 'cumsum'}).rename(
columns={'daily_sales': 'quarterly_sales'})
| quarterly_sales | |
|---|---|
| date | |
| 2018-01-01 | 6766.16 |
| 2018-01-02 | 8318.07 |
| 2018-01-03 | 12597.03 |
| 2018-01-04 | 18641.13 |
| 2018-01-05 | 20613.07 |
| ... | ... |
| 2018-12-27 | 480817.47 |
| 2018-12-28 | 484389.92 |
| 2018-12-29 | 489227.01 |
| 2018-12-30 | 494106.67 |
| 2018-12-31 | 496069.30 |
365 rows × 1 columns
В этом примере я включил именованный подход агрегации (named aggregation approach), чтобы переименовать переменную и уточнить, что теперь это ежедневные продажи. Затем я снова группирую и использую совокупную (cumulative) сумму, чтобы получить текущую сумму за квартал. Наконец, я переименовал столбец в квартальные продажи (quarterly sales).
По отзывам, на первый взгляд, это сложно понять. Однако, если выполните по шагам, т.е. построите функцию и будете проверять результаты на каждом шаге, то начнете понимать ее.
Не расстраивайтесь!
По умолчанию pandas в сводном DataFrame создает иерархический индекс у столбца:
df.groupby(['embark_town', 'class']).agg({'fare': ['sum', 'mean']}).round()
| fare | |||
|---|---|---|---|
| sum | mean | ||
| embark_town | class | ||
| Cherbourg | First | 8901.0 | 105.0 |
| Second | 431.0 | 25.0 | |
| Third | 740.0 | 11.0 | |
| Queenstown | First | 180.0 | 90.0 |
| Second | 37.0 | 12.0 | |
| Third | 805.0 | 11.0 | |
| Southampton | First | 8936.0 | 70.0 |
| Second | 3334.0 | 20.0 | |
| Third | 5169.0 | 15.0 | |
В какой-то момент в процессе анализа вы, вероятно, захотите «сгладить» (flatten) столбцы, чтобы получилась одна строка с именами.
Я обнаружил, что мне лучше всего подходит следующий подход.
Я использую параметр as_index=False при группировке, а затем создаю новое имя свернутого (collapsed) столбца.
Вот код:
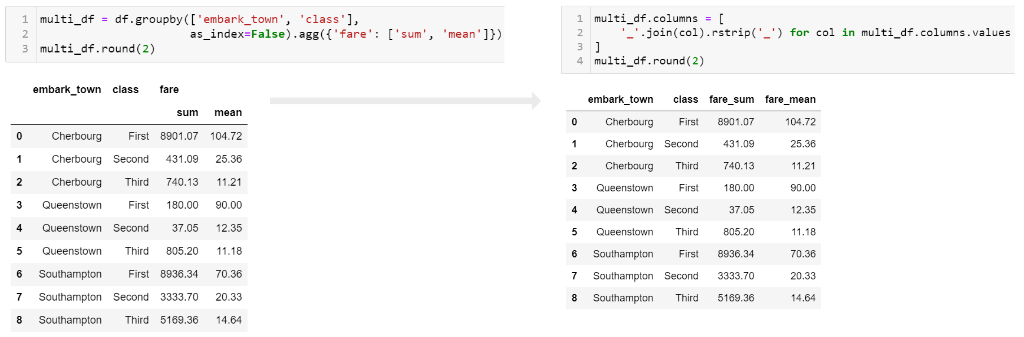
multi_df = df.groupby(['embark_town', 'class'], as_index=False).agg({'fare': ['sum', 'mean']})
multi_df
| embark_town | class | fare | ||
|---|---|---|---|---|
| sum | mean | |||
| 0 | Cherbourg | First | 8901.0750 | 104.718529 |
| 1 | Cherbourg | Second | 431.0917 | 25.358335 |
| 2 | Cherbourg | Third | 740.1295 | 11.214083 |
| 3 | Queenstown | First | 180.0000 | 90.000000 |
| 4 | Queenstown | Second | 37.0500 | 12.350000 |
| 5 | Queenstown | Third | 805.2043 | 11.183393 |
| 6 | Southampton | First | 8936.3375 | 70.364862 |
| 7 | Southampton | Second | 3333.7000 | 20.327439 |
| 8 | Southampton | Third | 5169.3613 | 14.644083 |
multi_df.columns = ['_'.join(col).rstrip('_') for col in multi_df.columns.values]
multi_df.round(2)
| embark_town | class | fare_sum | fare_mean | |
|---|---|---|---|---|
| 0 | Cherbourg | First | 8901.07 | 104.72 |
| 1 | Cherbourg | Second | 431.09 | 25.36 |
| 2 | Cherbourg | Third | 740.13 | 11.21 |
| 3 | Queenstown | First | 180.00 | 90.00 |
| 4 | Queenstown | Second | 37.05 | 12.35 |
| 5 | Queenstown | Third | 805.20 | 11.18 |
| 6 | Southampton | First | 8936.34 | 70.36 |
| 7 | Southampton | Second | 3333.70 | 20.33 |
| 8 | Southampton | Third | 5169.36 | 14.64 |
Вот изображение, показывающее, как выглядит сплющенный кадр данных:
Я предпочитаю использовать _ в качестве разделителя, но вы можете использовать другие значения. Просто имейте в виду, что для последующего анализа будет проще, если в именах результирующих столбцов нет пробелов.
#!pip3 install sidetable
import sidetable
df.groupby(['class', 'embark_town', 'sex']).agg({'fare': 'sum'}).stb.subtotal()
| fare | |||
|---|---|---|---|
| class | embark_town | sex | |
| First | Cherbourg | female | 4972.5333 |
| male | 3928.5417 | ||
| First | Cherbourg - subtotal | 8901.0750 | ||
| Queenstown | female | 90.0000 | |
| male | 90.0000 | ||
| First | Queenstown - subtotal | 180.0000 | ||
| Southampton | female | 4753.2917 | |
| male | 4183.0458 | ||
| First | Southampton - subtotal | 8936.3375 | ||
| First - subtotal | 18017.4125 | ||
| Second | Cherbourg | female | 176.8792 |
| male | 254.2125 | ||
| Second | Cherbourg - subtotal | 431.0917 | ||
| Queenstown | female | 24.7000 | |
| male | 12.3500 | ||
| Second | Queenstown - subtotal | 37.0500 | ||
| Southampton | female | 1468.1500 | |
| male | 1865.5500 | ||
| Second | Southampton - subtotal | 3333.7000 | ||
| Second - subtotal | 3801.8417 | ||
| Third | Cherbourg | female | 337.9833 |
| male | 402.1462 | ||
| Third | Cherbourg - subtotal | 740.1295 | ||
| Queenstown | female | 340.1585 | |
| male | 465.0458 | ||
| Third | Queenstown - subtotal | 805.2043 | ||
| Southampton | female | 1642.9668 | |
| male | 3526.3945 | ||
| Third | Southampton - subtotal | 5169.3613 | ||
| Third - subtotal | 6714.6951 | ||
| grand_total | 28533.9493 |
sidetable также позволяет настраивать уровни промежуточных итогов и итоговые метки. Обратитесь к документации пакета для получения дополнительных примеров того, как sidetable может резюмировать данные.
Спасибо, что прочитали эту статью. Здесь много деталей, но это связано с тем, что существует множество различных применений для группировки и агрегирования данных с помощью pandas. Я надеюсь, что этот пост станет полезным ресурсом, который вы сможете добавить в закладки и вернуться к нему, когда столкнетесь с собственной сложной проблемой.
Если у вас есть другие распространенные техники, которые вы часто используете, дайте мне знать в комментариях к статье. Если я получу что-нибудь полезное, я включу его в этот пост или как обновленную статью.