![]()
![]()
Оригинал статьи доступен по ссылке
Недавно я наткнулся на статью Хэдли Уикхэма (Hadley Wickham) под названием Tidy Data (Аккуратные Данные).
Документ, опубликованный еще в 2014 году, посвящен одному аспекту очистки данных, упорядочиванию: структурированию наборов данных для упрощения анализа. В документе Уикхэм демонстрирует, как любой набор данных может быть структурирован до проведения анализа. Он подробно описывает различные типы наборов данных и способы их преобразования в стандартный формат.
Очистка данных - одна из самых частых задач в области науки о данных. Независимо от того, с какими данными вы имеете дело или какой анализ вы выполняете, в какой-то момент вам придется очистить данные. Приведение данных в порядок упрощает работу в будущем.
Библиотеки для построения графиков
AltairиPlotlyна входе принимают фреймы данных в аккуратном формате.
В этой заметке я обобщу некоторые примеры наведения порядка, которые Уикхэм использует в своей статье, и продемонстрирую, как это сделать с помощью Python и pandas.
Структура, которую Уикхэм определяет как аккуратная (tidy), имеет следующие атрибуты:
variable) образует столбец и содержит значения (values).observation) образует строку.observational unit) составляет таблицу.Несколько определений:
Пример беспорядочного набора данных (messy dataset):

Пример аккуратного набора данных (tidy dataset):
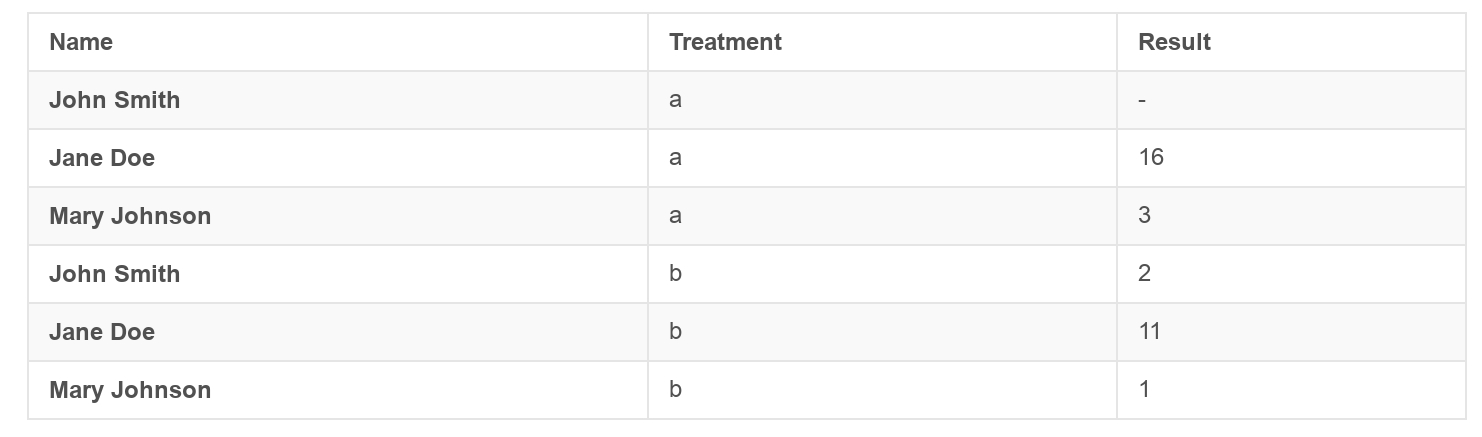
С помощью следующих примеров, взятых из статьи Уикхема, мы преобразуем беспорядочные наборы данных в аккуратный формат. Цель здесь не в том, чтобы проанализировать наборы данных, а, скорее, в их стандартизированной подготовке перед анализом.
Рассмотрим пять типов беспорядочных наборов данных:
1) Заголовки столбцов - это значения, а не имена переменных.
2) Несколько переменных хранятся в одном столбце.
3) Переменные хранятся как в строках, так и в столбцах.
4) В одной таблице хранятся несколько единиц объектов наблюдения (observational units).
5) Одна единица наблюдения хранится в нескольких таблицах.
Набор данных Pew Research Center
Этот набор данных исследует взаимосвязь между доходом и религией.
Проблема: заголовки столбцов состоят из возможных значений дохода.
import pandas as pd
import datetime
from os import listdir
from os.path import isfile, join
import glob
import re
df = pd.read_csv("https://github.com/dm-fedorov/pandas_basic/blob/master/data/tidy_data/pew-raw.csv?raw=True")
df.head()
| religion | <$10k | $10-20k | $20-30k | $30-40k | $40-50k | $50-75k | |
|---|---|---|---|---|---|---|---|
| 0 | Agnostic | 27 | 34 | 60 | 81 | 76 | 137 |
| 1 | Atheist | 12 | 27 | 37 | 52 | 35 | 70 |
| 2 | Buddhist | 27 | 21 | 30 | 34 | 33 | 58 |
| 3 | Catholic | 418 | 617 | 732 | 670 | 638 | 1116 |
| 4 | Dont know/refused | 15 | 14 | 15 | 11 | 10 | 35 |
Аккуратная версия этого набора данных - та, в которой значения дохода будут не заголовками столбцов, а значениями в столбце дохода. Чтобы привести в порядок этот набор данных, нам нужно его растопить (melt).
В библиотеке pandas есть встроенная функция melt, которая позволяет это сделать.
Она "переворачивает" (unpivots) фрейм данных (DataFrame) из широкого формата (wide format) в длинный (long format).
formatted_df = pd.melt(df, ["religion"], var_name="income", value_name="freq")
formatted_df = formatted_df.sort_values(by=["religion"])
# выводим аккуратную версию набора данных:
formatted_df.head()
| religion | income | freq | |
|---|---|---|---|
| 0 | Agnostic | <$10k | 27 |
| 30 | Agnostic | $30-40k | 81 |
| 40 | Agnostic | $40-50k | 76 |
| 50 | Agnostic | $50-75k | 137 |
| 10 | Agnostic | $10-20k | 34 |
Набор данных Billboard Top 100
Этот набор данных представляет собой еженедельный рейтинг песен с момента их попадания в Billboard Top 100 до последующих 75 недель.
Проблемы:
x1st.week,…)df = pd.read_csv("https://github.com/dm-fedorov/pandas_basic/blob/master/data/tidy_data/billboard.csv?raw=True",
encoding="mac_latin2")
df.head()
| year | artist.inverted | track | time | genre | date.entered | date.peaked | x1st.week | x2nd.week | x3rd.week | ... | x67th.week | x68th.week | x69th.week | x70th.week | x71st.week | x72nd.week | x73rd.week | x74th.week | x75th.week | x76th.week | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2000 | Destiny's Child | Independent Women Part I | 3:38 | Rock | 2000-09-23 | 2000-11-18 | 78 | 63.0 | 49.0 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | 2000 | Santana | Maria, Maria | 4:18 | Rock | 2000-02-12 | 2000-04-08 | 15 | 8.0 | 6.0 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 2000 | Savage Garden | I Knew I Loved You | 4:07 | Rock | 1999-10-23 | 2000-01-29 | 71 | 48.0 | 43.0 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 2000 | Madonna | Music | 3:45 | Rock | 2000-08-12 | 2000-09-16 | 41 | 23.0 | 18.0 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 2000 | Aguilera, Christina | Come On Over Baby (All I Want Is You) | 3:38 | Rock | 2000-08-05 | 2000-10-14 | 57 | 47.0 | 45.0 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
5 rows × 83 columns
df.columns
Index(['year', 'artist.inverted', 'track', 'time', 'genre', 'date.entered',
'date.peaked', 'x1st.week', 'x2nd.week', 'x3rd.week', 'x4th.week',
'x5th.week', 'x6th.week', 'x7th.week', 'x8th.week', 'x9th.week',
'x10th.week', 'x11th.week', 'x12th.week', 'x13th.week', 'x14th.week',
'x15th.week', 'x16th.week', 'x17th.week', 'x18th.week', 'x19th.week',
'x20th.week', 'x21st.week', 'x22nd.week', 'x23rd.week', 'x24th.week',
'x25th.week', 'x26th.week', 'x27th.week', 'x28th.week', 'x29th.week',
'x30th.week', 'x31st.week', 'x32nd.week', 'x33rd.week', 'x34th.week',
'x35th.week', 'x36th.week', 'x37th.week', 'x38th.week', 'x39th.week',
'x40th.week', 'x41st.week', 'x42nd.week', 'x43rd.week', 'x44th.week',
'x45th.week', 'x46th.week', 'x47th.week', 'x48th.week', 'x49th.week',
'x50th.week', 'x51st.week', 'x52nd.week', 'x53rd.week', 'x54th.week',
'x55th.week', 'x56th.week', 'x57th.week', 'x58th.week', 'x59th.week',
'x60th.week', 'x61st.week', 'x62nd.week', 'x63rd.week', 'x64th.week',
'x65th.week', 'x66th.week', 'x67th.week', 'x68th.week', 'x69th.week',
'x70th.week', 'x71st.week', 'x72nd.week', 'x73rd.week', 'x74th.week',
'x75th.week', 'x76th.week'],
dtype='object')
Для приведения этих данных к аккуратным мы снова растопим (melt) столбцы недель в один столбец date.
Создадим одну строку в неделю для каждой записи. Если данных за данную неделю нет, то строку создавать не будем.
# Melting
id_vars = ["year", "artist.inverted", "track", "time", "genre", "date.entered", "date.peaked"]
df = pd.melt(frame=df, id_vars=id_vars, var_name="week", value_name="rank_")
df.head()
| year | artist.inverted | track | time | genre | date.entered | date.peaked | week | rank_ | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2000 | Destiny's Child | Independent Women Part I | 3:38 | Rock | 2000-09-23 | 2000-11-18 | x1st.week | 78.0 |
| 1 | 2000 | Santana | Maria, Maria | 4:18 | Rock | 2000-02-12 | 2000-04-08 | x1st.week | 15.0 |
| 2 | 2000 | Savage Garden | I Knew I Loved You | 4:07 | Rock | 1999-10-23 | 2000-01-29 | x1st.week | 71.0 |
| 3 | 2000 | Madonna | Music | 3:45 | Rock | 2000-08-12 | 2000-09-16 | x1st.week | 41.0 |
| 4 | 2000 | Aguilera, Christina | Come On Over Baby (All I Want Is You) | 3:38 | Rock | 2000-08-05 | 2000-10-14 | x1st.week | 57.0 |
df["week"]
0 x1st.week
1 x1st.week
2 x1st.week
3 x1st.week
4 x1st.week
...
24087 x76th.week
24088 x76th.week
24089 x76th.week
24090 x76th.week
24091 x76th.week
Name: week, Length: 24092, dtype: object
# Форматирование
df["week"] = df['week'].str.extract('(\d+)', expand=False).astype(int)
# Удаление ненужных строк
df = df.dropna()
# Создаем столбцы "date"
df['date'] = pd.to_datetime(df['date.entered']) + pd.to_timedelta(df['week'], unit='w') - pd.DateOffset(weeks=1)
df = df[["year", "artist.inverted", "track", "time", "genre", "week", "rank_", "date"]]
df = df.sort_values(ascending=True, by=["year", "artist.inverted", "track", "week", "rank_"])
df["rank"] = df["rank_"].astype(int)
df = df.drop(["rank_"], axis=1)
# Назначение аккуратного набора данных переменной billboard для использования в будущем
billboard = df
df.head()
| year | artist.inverted | track | time | genre | week | date | rank | |
|---|---|---|---|---|---|---|---|---|
| 246 | 2000 | 2 Pac | Baby Don't Cry (Keep Ya Head Up II) | 4:22 | Rap | 1 | 2000-02-26 | 87 |
| 563 | 2000 | 2 Pac | Baby Don't Cry (Keep Ya Head Up II) | 4:22 | Rap | 2 | 2000-03-04 | 82 |
| 880 | 2000 | 2 Pac | Baby Don't Cry (Keep Ya Head Up II) | 4:22 | Rap | 3 | 2000-03-11 | 72 |
| 1197 | 2000 | 2 Pac | Baby Don't Cry (Keep Ya Head Up II) | 4:22 | Rap | 4 | 2000-03-18 | 77 |
| 1514 | 2000 | 2 Pac | Baby Don't Cry (Keep Ya Head Up II) | 4:22 | Rap | 5 | 2000-03-25 | 87 |
По-прежнему часто повторяются детали песни: track, time и genre.
По этой причине набор данных все еще не совсем аккуратный в соответствии с определением Уикхема. Мы рассмотрим его снова в следующем примере.
Следуя за набором данных Billboard, рассмотрим проблему повторения из предыдущей таблицы.
Проблемы:
track и ее rank) в одной таблице.Сначала создадим таблицу песен, которая будет содержать сведения о каждой песне:
songs_cols = ["year", "artist.inverted", "track", "time", "genre"]
songs = billboard[songs_cols].drop_duplicates()
songs = songs.reset_index(drop=True)
songs["song_id"] = songs.index
songs.head()
| year | artist.inverted | track | time | genre | song_id | |
|---|---|---|---|---|---|---|
| 0 | 2000 | 2 Pac | Baby Don't Cry (Keep Ya Head Up II) | 4:22 | Rap | 0 |
| 1 | 2000 | 2Ge+her | The Hardest Part Of Breaking Up (Is Getting Ba... | 3:15 | R&B | 1 |
| 2 | 2000 | 3 Doors Down | Kryptonite | 3:53 | Rock | 2 |
| 3 | 2000 | 3 Doors Down | Loser | 4:24 | Rock | 3 |
| 4 | 2000 | 504 Boyz | Wobble Wobble | 3:35 | Rap | 4 |
Затем создадим таблицу ranks, которая будет содержать только song_id, date и rank.
ranks = pd.merge(billboard, songs, on=["year", "artist.inverted", "track", "time", "genre"])
ranks = ranks[["song_id", "date", "rank"]]
ranks.head()
| song_id | date | rank | |
|---|---|---|---|
| 0 | 0 | 2000-02-26 | 87 |
| 1 | 0 | 2000-03-04 | 82 |
| 2 | 0 | 2000-03-11 | 72 |
| 3 | 0 | 2000-03-18 | 77 |
| 4 | 0 | 2000-03-25 | 87 |
Записи по туберкулёзу от Всемирной организации здравоохранения
Этот набор данных документирует количество подтвержденных случаев туберкулеза по странам, годам, возрасту и полу.
Проблемы:
m или f) и возраст (0–14, 15–24, 25–34, 45–54, 55–64, 65, unknown).NaN. Это связано с процессом сбора данных, и для этого набора данных важно различие.df = pd.read_csv("https://github.com/dm-fedorov/pandas_basic/blob/master/data/tidy_data/tb-raw.csv?raw=True")
df.head()
| country | year | m014 | m1524 | m2534 | m3544 | m4554 | m5564 | m65 | mu | f014 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | AD | 2000 | 0.0 | 0.0 | 1.0 | 0.0 | 0 | 0 | 0.0 | NaN | NaN |
| 1 | AE | 2000 | 2.0 | 4.0 | 4.0 | 6.0 | 5 | 12 | 10.0 | NaN | 3.0 |
| 2 | AF | 2000 | 52.0 | 228.0 | 183.0 | 149.0 | 129 | 94 | 80.0 | NaN | 93.0 |
| 3 | AG | 2000 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 0 | 1.0 | NaN | 1.0 |
| 4 | AL | 2000 | 2.0 | 19.0 | 21.0 | 14.0 | 24 | 19 | 16.0 | NaN | 3.0 |
Чтобы привести в порядок этот набор данных, нужно удалить значения из заголовка и преобразовать их в строки.
Сначала нужно расплавить (melt) столбцы, содержащие пол и возраст. Как только у нас будет единственный столбец, мы получим из него три столбца: sex, age_lower и age_upper.
Затем с их помощью сможем правильно построить аккуратный набор данных.
df = pd.melt(df, id_vars=["country", "year"], value_name="cases", var_name="sex_and_age")
# Извлечь пол, нижнюю границу возраста и группу верхней границы возраста
tmp_df = df["sex_and_age"].str.extract("(\D)(\d+)(\d{2})", expand=False)
# Столбцы имени
tmp_df.columns = ["sex", "age_lower", "age_upper"]
# Создайте столбец age на основе age_lower и age_upper
tmp_df["age"] = tmp_df["age_lower"] + "-" + tmp_df["age_upper"]
# Merge
df = pd.concat([df, tmp_df], axis=1)
# Удалите ненужные столбцы и строки
df = df.drop(['sex_and_age', "age_lower", "age_upper"], axis=1)
df = df.dropna()
df = df.sort_values(ascending=True,by=["country", "year", "sex", "age"])
# В результате получается аккуратный набор данных
df.head()
| country | year | cases | sex | age | |
|---|---|---|---|---|---|
| 0 | AD | 2000 | 0.0 | m | 0-14 |
| 10 | AD | 2000 | 0.0 | m | 15-24 |
| 20 | AD | 2000 | 1.0 | m | 25-34 |
| 30 | AD | 2000 | 0.0 | m | 35-44 |
| 40 | AD | 2000 | 0.0 | m | 45-54 |
Набор сетевых данных по глобальной исторической климатологии (Global Historical Climatology Network Dataset)
Этот набор данных представляет собой ежедневные записи погоды для метеостанции (MX17004) в Мексике за пять месяцев в 2010 году.
Проблемы:
tmin, tmax), так и в столбцах (days).df = pd.read_csv("https://github.com/dm-fedorov/pandas_basic/blob/master/data/tidy_data/weather-raw.csv?raw=True")
df.head()
| id | year | month | element | d1 | d2 | d3 | d4 | d5 | d6 | d7 | d8 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | MX17004 | 2010 | 1 | tmax | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | MX17004 | 2010 | 1 | tmin | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | MX17004 | 2010 | 2 | tmax | NaN | 27.3 | 24.1 | NaN | NaN | NaN | NaN | NaN |
| 3 | MX17004 | 2010 | 2 | tmin | NaN | 14.4 | 14.4 | NaN | NaN | NaN | NaN | NaN |
| 4 | MX17004 | 2010 | 3 | tmax | NaN | NaN | NaN | NaN | 32.1 | NaN | NaN | NaN |
df = pd.melt(df, id_vars=["id", "year", "month", "element"], var_name="day_raw")
df.head()
| id | year | month | element | day_raw | value | |
|---|---|---|---|---|---|---|
| 0 | MX17004 | 2010 | 1 | tmax | d1 | NaN |
| 1 | MX17004 | 2010 | 1 | tmin | d1 | NaN |
| 2 | MX17004 | 2010 | 2 | tmax | d1 | NaN |
| 3 | MX17004 | 2010 | 2 | tmin | d1 | NaN |
| 4 | MX17004 | 2010 | 3 | tmax | d1 | NaN |
Чтобы упорядочить этот набор данных, мы хотим переместить три неуместных переменных (tmin, tmax и days) в виде трех отдельных столбцов: tmin, tmax и date.
# Извлекаем день
df["day"] = df["day_raw"].str.extract("d(\d+)", expand=False)
df["id"] = "MX17004"
# К числовым значениям
df[["year", "month", "day"]] = df[["year", "month", "day"]].apply(lambda x: pd.to_numeric(x, errors='ignore'))
# Создание даты из разных столбцов
def create_date_from_year_month_day(row):
return datetime.datetime(year=row["year"], month=int(row["month"]), day=row["day"])
df["date"] = df.apply(lambda row: create_date_from_year_month_day(row), axis=1)
df = df.drop(['year', "month", "day", "day_raw"], axis=1)
df = df.dropna()
# Unmelting столбец "element"
df = df.pivot_table(index=["id", "date"], columns="element", values="value")
df.reset_index(drop=False, inplace=True)
df.head()
| element | id | date | tmax | tmin |
|---|---|---|---|---|
| 0 | MX17004 | 2010-02-02 | 27.3 | 14.4 |
| 1 | MX17004 | 2010-02-03 | 24.1 | 14.4 |
| 2 | MX17004 | 2010-03-05 | 32.1 | 14.2 |
Набор данных: имена мальчиков в штате Иллинойс за 2014/15 годы
Проблемы:
year.Чтобы загрузить разные файлы в один DataFrame, мы можем запустить собственный скрипт, который будет добавлять файлы вместе. Кроме того, нам нужно будет извлечь переменную year из имени файла.
Следующий пример подразумевает наличие двух файлов в корневой директории:
2015-baby-names-illinois.csvи2014-baby-names-illinois.csv
!wget https://raw.githubusercontent.com/dm-fedorov/pandas_basic/master/data/tidy_data/2015-baby-names-illinois.csv
!wget https://raw.githubusercontent.com/dm-fedorov/pandas_basic/master/data/tidy_data/2014-baby-names-illinois.csv
def extract_year(string):
match = re.match(".+(\d{4})", string)
if match != None:
return match.group(1)
path = '.' # текущая директория
allFiles = glob.glob(path + "/201*-baby-names-illinois.csv")
frame = pd.DataFrame()
df_list= []
for file_ in allFiles:
df = pd.read_csv(file_, index_col=None, header=0)
df.columns = map(str.lower, df.columns)
df["year"] = extract_year(file_)
df_list.append(df)
df = pd.concat(df_list)
df.head()
| rank | name | frequency | sex | year | |
|---|---|---|---|---|---|
| 0 | 1 | Noah | 863 | Male | 2015 |
| 1 | 2 | Liam | 709 | Male | 2015 |
| 2 | 3 | Alexander | 703 | Male | 2015 |
| 3 | 4 | Jacob | 650 | Male | 2015 |
| 4 | 5 | William | 618 | Male | 2015 |
В этой заметке я сосредоточился только на одном аспекте статьи Уикхема, а именно на части манипулирования данными. Моей главной целью было продемонстрировать манипуляции с данными в Python. Важно отметить, что в статье Уикхема есть значительный раздел, посвященный инструментам и визуализациям, с помощью которых вы можете извлечь пользу, приведя в порядок свой набор данных.