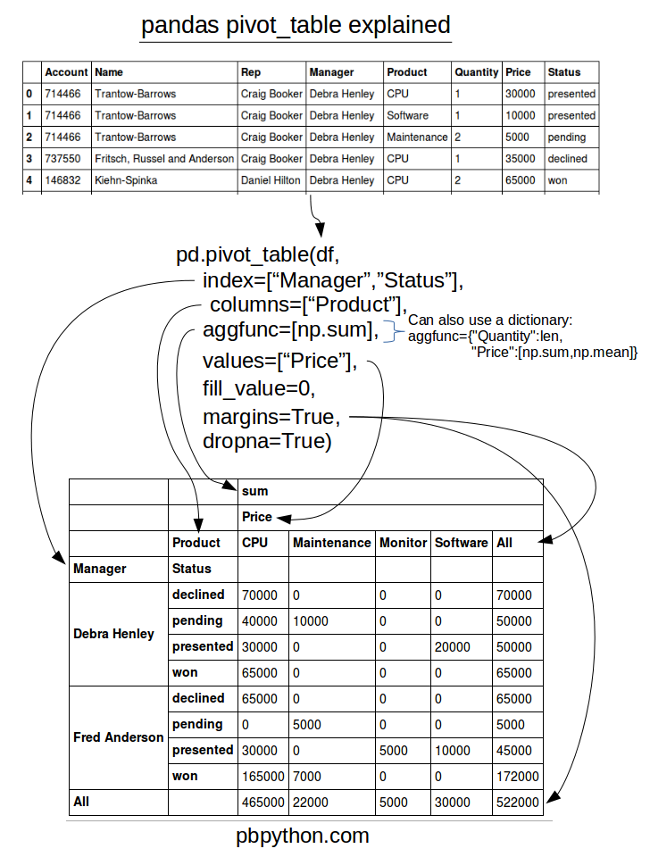
Сводная таблица - это мощный инструмент для обобщения и представления данных.
В Pandas есть функция DataFrame.pivot_table(), которая позволяет быстро преобразовать DataFrame в сводную таблицу.
Обобщенная схема работы функции pivot_table:
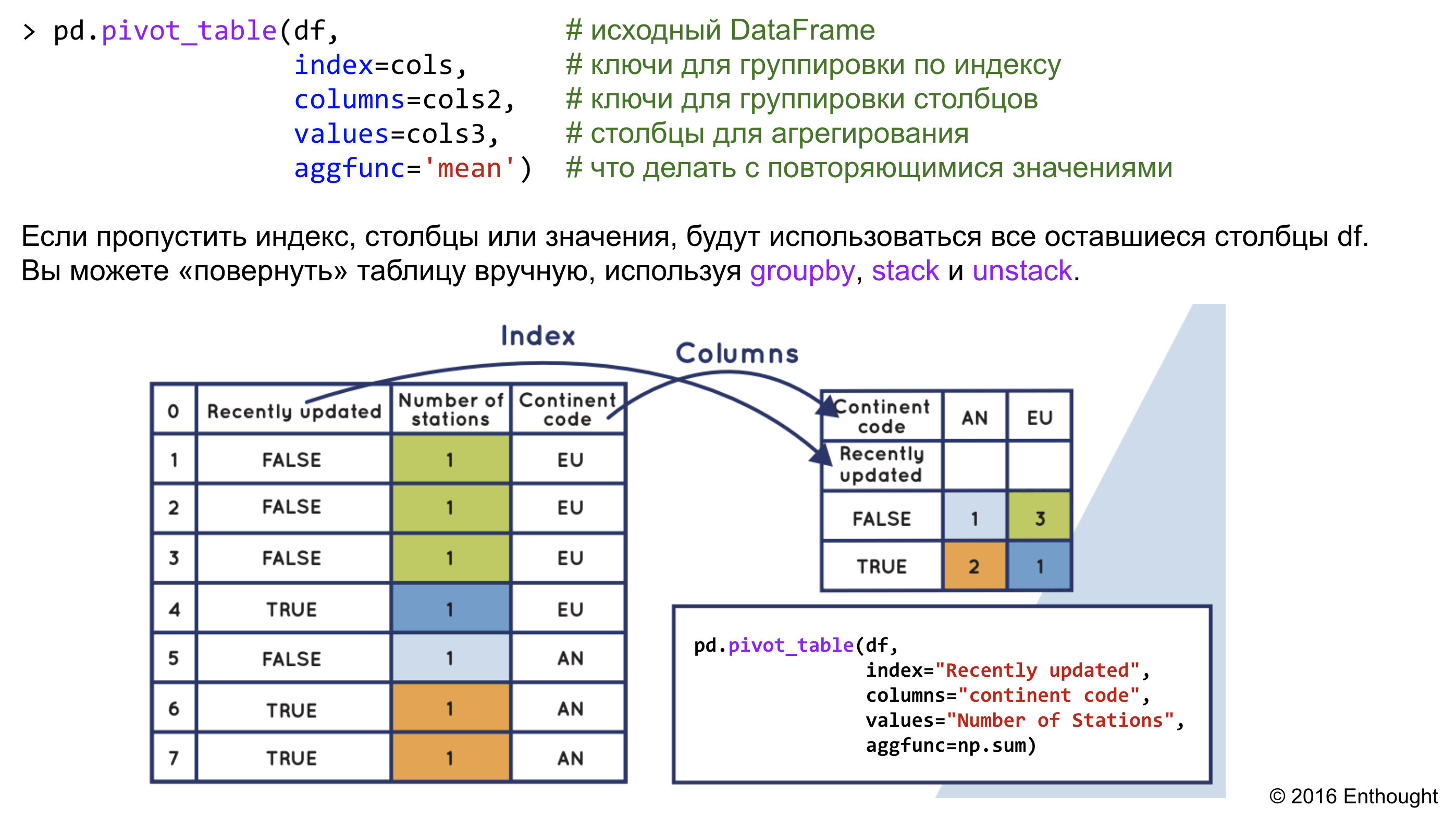
Эта функция очень полезна, но иногда бывает сложно запомнить, как ее использовать для форматирования данных нужным вам способом.
В этом Блокноте рассказывается, как использовать pivot_table.
Полный текст оригинальной статьи находится здесь.
В этом сценарии я собираюсь отслеживать воронку (план) продаж (также называемую воронкой, funnel). Основная проблема заключается в том, что некоторые циклы продаж очень длинные (например, "корпоративное программное обеспечение", капитальное оборудование и т.д.), и руководство хочет отслеживать их детально в течение года.
Типичные вопросы, относящиеся к таким данным, включают:
import pandas as pd
import numpy as np
Прочтите данные о нашей воронке продаж в DataFrame:
df = pd.read_excel("https://github.com/dm-fedorov/pandas_basic/raw/master/%D0%B1%D1%8B%D1%81%D1%82%D1%80%D0%BE%D0%B5%20%D0%B2%D0%B2%D0%B5%D0%B4%D0%B5%D0%BD%D0%B8%D0%B5%20%D0%B2%20pandas/data/salesfunnel.xlsx")
df.head()
# Счет, Название компании, Представитель компании, Менеджер по продажам, Продукт, Кол-во, Стоимость, Статус сделки
| Account | Name | Rep | Manager | Product | Quantity | Price | Status | |
|---|---|---|---|---|---|---|---|---|
| 0 | 714466 | Trantow-Barrows | Craig Booker | Debra Henley | CPU | 1 | 30000 | presented |
| 1 | 714466 | Trantow-Barrows | Craig Booker | Debra Henley | Software | 1 | 10000 | presented |
| 2 | 714466 | Trantow-Barrows | Craig Booker | Debra Henley | Maintenance | 2 | 5000 | pending |
| 3 | 737550 | Fritsch, Russel and Anderson | Craig Booker | Debra Henley | CPU | 1 | 35000 | declined |
| 4 | 146832 | Kiehn-Spinka | Daniel Hilton | Debra Henley | CPU | 2 | 65000 | won |
Для удобства давайте представим столбец Status как категориальную переменную (category) и установим порядок, в котором хотим просматривать.
Это не является строго обязательным, но помогает поддерживать желаемый порядок при работе с данными.
df["Status"] = df["Status"].astype("category")
df["Status"].cat.set_categories(["won", "pending", "presented", "declined"], inplace=True)
df.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 17 entries, 0 to 16 Data columns (total 8 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Account 17 non-null int64 1 Name 17 non-null object 2 Rep 17 non-null object 3 Manager 17 non-null object 4 Product 17 non-null object 5 Quantity 17 non-null int64 6 Price 17 non-null int64 7 Status 17 non-null category dtypes: category(1), int64(3), object(4) memory usage: 1.3+ KB
Создавать сводную таблицу (pivot table) проще всего последовательно. Добавляйте элементы по одному и проверяйте каждый шаг, чтобы убедиться, что вы получаете ожидаемые результаты.
Самая простая сводная таблица должна иметь DataFrame и индекс (index). В этом примере давайте использовать Name в качестве индекса:
pd.pivot_table(df,
index=["Name"])
| Account | Price | Quantity | |
|---|---|---|---|
| Name | |||
| Barton LLC | 740150 | 35000 | 1.000000 |
| Fritsch, Russel and Anderson | 737550 | 35000 | 1.000000 |
| Herman LLC | 141962 | 65000 | 2.000000 |
| Jerde-Hilpert | 412290 | 5000 | 2.000000 |
| Kassulke, Ondricka and Metz | 307599 | 7000 | 3.000000 |
| Keeling LLC | 688981 | 100000 | 5.000000 |
| Kiehn-Spinka | 146832 | 65000 | 2.000000 |
| Koepp Ltd | 729833 | 35000 | 2.000000 |
| Kulas Inc | 218895 | 25000 | 1.500000 |
| Purdy-Kunde | 163416 | 30000 | 1.000000 |
| Stokes LLC | 239344 | 7500 | 1.000000 |
| Trantow-Barrows | 714466 | 15000 | 1.333333 |
У вас может быть несколько индексов. Фактически, большинство аргументов pivot_table могут принимать несколько значений в качестве элементов списка:
pd.pivot_table(df,
index=["Name", "Rep", "Manager"])
| Account | Price | Quantity | |||
|---|---|---|---|---|---|
| Name | Rep | Manager | |||
| Barton LLC | John Smith | Debra Henley | 740150 | 35000 | 1.000000 |
| Fritsch, Russel and Anderson | Craig Booker | Debra Henley | 737550 | 35000 | 1.000000 |
| Herman LLC | Cedric Moss | Fred Anderson | 141962 | 65000 | 2.000000 |
| Jerde-Hilpert | John Smith | Debra Henley | 412290 | 5000 | 2.000000 |
| Kassulke, Ondricka and Metz | Wendy Yule | Fred Anderson | 307599 | 7000 | 3.000000 |
| Keeling LLC | Wendy Yule | Fred Anderson | 688981 | 100000 | 5.000000 |
| Kiehn-Spinka | Daniel Hilton | Debra Henley | 146832 | 65000 | 2.000000 |
| Koepp Ltd | Wendy Yule | Fred Anderson | 729833 | 35000 | 2.000000 |
| Kulas Inc | Daniel Hilton | Debra Henley | 218895 | 25000 | 1.500000 |
| Purdy-Kunde | Cedric Moss | Fred Anderson | 163416 | 30000 | 1.000000 |
| Stokes LLC | Cedric Moss | Fred Anderson | 239344 | 7500 | 1.000000 |
| Trantow-Barrows | Craig Booker | Debra Henley | 714466 | 15000 | 1.333333 |
Это интересно, но не особо полезно.
Мы хотим посмотреть на эти данные со стороны менеджера (Manager) и директора (Director). Это достаточно просто сделать, изменив индекс:
pd.pivot_table(df,
index=["Manager", "Rep"])
| Account | Price | Quantity | ||
|---|---|---|---|---|
| Manager | Rep | |||
| Debra Henley | Craig Booker | 720237.0 | 20000.000000 | 1.250000 |
| Daniel Hilton | 194874.0 | 38333.333333 | 1.666667 | |
| John Smith | 576220.0 | 20000.000000 | 1.500000 | |
| Fred Anderson | Cedric Moss | 196016.5 | 27500.000000 | 1.250000 |
| Wendy Yule | 614061.5 | 44250.000000 | 3.000000 |
Вы могли заметить, что сводная таблица достаточно умна, чтобы начать агрегирование данных и их обобщение, группируя представителей (Rep) с их менеджерами (Manager). Теперь мы начинаем понимать, что может сделать для нас сводная таблица.
Давайте удалим счет (Account) и количество (Quantity), явно определив столбцы, которые нам нужны, с помощью параметра values:
pd.pivot_table(df,
index=["Manager", "Rep"],
values=["Price"])
| Price | ||
|---|---|---|
| Manager | Rep | |
| Debra Henley | Craig Booker | 20000.000000 |
| Daniel Hilton | 38333.333333 | |
| John Smith | 20000.000000 | |
| Fred Anderson | Cedric Moss | 27500.000000 |
| Wendy Yule | 44250.000000 |
Столбец цен (price) по умолчанию усредняет данные, но мы можем произвести подсчет количества или суммы. Добавить их можно с помощью параметра aggfunc:
pd.pivot_table(df,
index=["Manager", "Rep"],
values=["Price"],
aggfunc=np.sum)
| Price | ||
|---|---|---|
| Manager | Rep | |
| Debra Henley | Craig Booker | 80000 |
| Daniel Hilton | 115000 | |
| John Smith | 40000 | |
| Fred Anderson | Cedric Moss | 110000 |
| Wendy Yule | 177000 |
aggfunc может принимать список функций.
Давайте попробуем узнать среднее значение и количество:
pd.pivot_table(df,
index=["Manager", "Rep"],
values=["Price"],
aggfunc=[np.mean, len])
| mean | len | ||
|---|---|---|---|
| Price | Price | ||
| Manager | Rep | ||
| Debra Henley | Craig Booker | 20000.000000 | 4 |
| Daniel Hilton | 38333.333333 | 3 | |
| John Smith | 20000.000000 | 2 | |
| Fred Anderson | Cedric Moss | 27500.000000 | 4 |
| Wendy Yule | 44250.000000 | 4 |
Если мы хотим увидеть продажи с разбивкой по продуктам (Product), переменная columns позволяет нам определить один или несколько столбцов.
Я думаю, что одна из сложностей pivot_table - это использование столбцов (columns) и значений (values).
Помните, что столбцы необязательны - они предоставляют дополнительный способ сегментировать актуальные значения, которые вам нужны.
Функции агрегирования применяются к перечисленным значениям (values):
pd.pivot_table(df,
index=["Manager", "Rep"],
values=["Price"],
columns=["Product"],
aggfunc=[np.sum])
| sum | |||||
|---|---|---|---|---|---|
| Price | |||||
| Product | CPU | Maintenance | Monitor | Software | |
| Manager | Rep | ||||
| Debra Henley | Craig Booker | 65000.0 | 5000.0 | NaN | 10000.0 |
| Daniel Hilton | 105000.0 | NaN | NaN | 10000.0 | |
| John Smith | 35000.0 | 5000.0 | NaN | NaN | |
| Fred Anderson | Cedric Moss | 95000.0 | 5000.0 | NaN | 10000.0 |
| Wendy Yule | 165000.0 | 7000.0 | 5000.0 | NaN | |
Значения NaN немного отвлекают. Если мы хотим их убрать, то можем использовать параметр fill_value, чтобы установить в 0.
pd.pivot_table(df,
index=["Manager", "Rep"],
values=["Price"],
columns=["Product"],
aggfunc=[np.sum],
fill_value=0)
| sum | |||||
|---|---|---|---|---|---|
| Price | |||||
| Product | CPU | Maintenance | Monitor | Software | |
| Manager | Rep | ||||
| Debra Henley | Craig Booker | 65000 | 5000 | 0 | 10000 |
| Daniel Hilton | 105000 | 0 | 0 | 10000 | |
| John Smith | 35000 | 5000 | 0 | 0 | |
| Fred Anderson | Cedric Moss | 95000 | 5000 | 0 | 10000 |
| Wendy Yule | 165000 | 7000 | 5000 | 0 | |
Думаю, было бы полезно добавить количество (Quantity).
Добавьте количество (Quantity) в список значений values:
pd.pivot_table(df,
index=["Manager", "Rep"],
values=["Price", "Quantity"],
columns=["Product"],
aggfunc=[np.sum],
fill_value=0)
| sum | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Price | Quantity | ||||||||
| Product | CPU | Maintenance | Monitor | Software | CPU | Maintenance | Monitor | Software | |
| Manager | Rep | ||||||||
| Debra Henley | Craig Booker | 65000 | 5000 | 0 | 10000 | 2 | 2 | 0 | 1 |
| Daniel Hilton | 105000 | 0 | 0 | 10000 | 4 | 0 | 0 | 1 | |
| John Smith | 35000 | 5000 | 0 | 0 | 1 | 2 | 0 | 0 | |
| Fred Anderson | Cedric Moss | 95000 | 5000 | 0 | 10000 | 3 | 1 | 0 | 1 |
| Wendy Yule | 165000 | 7000 | 5000 | 0 | 7 | 3 | 2 | 0 | |
Что интересно, вы можете добавлять элементы в индекс, чтобы получить другое визуальное представление.
Добавим товары (Products) в индекс.
pd.pivot_table(df,
index=["Manager", "Rep", "Product"],
values=["Price", "Quantity"],
aggfunc=[np.sum],
fill_value=0)
| sum | ||||
|---|---|---|---|---|
| Price | Quantity | |||
| Manager | Rep | Product | ||
| Debra Henley | Craig Booker | CPU | 65000 | 2 |
| Maintenance | 5000 | 2 | ||
| Software | 10000 | 1 | ||
| Daniel Hilton | CPU | 105000 | 4 | |
| Software | 10000 | 1 | ||
| John Smith | CPU | 35000 | 1 | |
| Maintenance | 5000 | 2 | ||
| Fred Anderson | Cedric Moss | CPU | 95000 | 3 |
| Maintenance | 5000 | 1 | ||
| Software | 10000 | 1 | ||
| Wendy Yule | CPU | 165000 | 7 | |
| Maintenance | 7000 | 3 | ||
| Monitor | 5000 | 2 | ||
Для этого набора данных такое представление имеет больше смысла.
А что, если я хочу увидеть некоторые итоги? margins=True делает это за нас.
pd.pivot_table(df,
index=["Manager", "Rep", "Product"],
values=["Price", "Quantity"],
aggfunc=[np.sum, np.mean],
fill_value=0,
margins=True)
| sum | mean | |||||
|---|---|---|---|---|---|---|
| Price | Quantity | Price | Quantity | |||
| Manager | Rep | Product | ||||
| Debra Henley | Craig Booker | CPU | 65000 | 2 | 32500.000000 | 1.000000 |
| Maintenance | 5000 | 2 | 5000.000000 | 2.000000 | ||
| Software | 10000 | 1 | 10000.000000 | 1.000000 | ||
| Daniel Hilton | CPU | 105000 | 4 | 52500.000000 | 2.000000 | |
| Software | 10000 | 1 | 10000.000000 | 1.000000 | ||
| John Smith | CPU | 35000 | 1 | 35000.000000 | 1.000000 | |
| Maintenance | 5000 | 2 | 5000.000000 | 2.000000 | ||
| Fred Anderson | Cedric Moss | CPU | 95000 | 3 | 47500.000000 | 1.500000 |
| Maintenance | 5000 | 1 | 5000.000000 | 1.000000 | ||
| Software | 10000 | 1 | 10000.000000 | 1.000000 | ||
| Wendy Yule | CPU | 165000 | 7 | 82500.000000 | 3.500000 | |
| Maintenance | 7000 | 3 | 7000.000000 | 3.000000 | ||
| Monitor | 5000 | 2 | 5000.000000 | 2.000000 | ||
| All | 522000 | 30 | 30705.882353 | 1.764706 | ||
Давайте переместим анализ на уровень выше и посмотрим на наш план продаж (воронку) на уровне менеджера.
Обратите внимание на то, как статус упорядочен на основе нашего предыдущего определения категории.
pd.pivot_table(df,
index=["Manager", "Status"],
values=["Price"],
aggfunc=[np.sum],
fill_value=0,
margins=True)
| sum | ||
|---|---|---|
| Price | ||
| Manager | Status | |
| Debra Henley | won | 65000 |
| pending | 50000 | |
| presented | 50000 | |
| declined | 70000 | |
| Fred Anderson | won | 172000 |
| pending | 5000 | |
| presented | 45000 | |
| declined | 65000 | |
| All | 522000 |
Очень удобно передать словарь в качестве aggfunc, чтобы вы могли выполнять разные функции с каждым из выбранных значений. Это имеет побочный эффект - названия становятся немного чище:
pd.pivot_table(df,
index=["Manager", "Status"],
columns=["Product"],
values=["Quantity", "Price"],
aggfunc={"Quantity": len, "Price": np.sum},
fill_value=0)
| Price | Quantity | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Product | CPU | Maintenance | Monitor | Software | CPU | Maintenance | Monitor | Software | |
| Manager | Status | ||||||||
| Debra Henley | won | 65000 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| pending | 40000 | 10000 | 0 | 0 | 1 | 2 | 0 | 0 | |
| presented | 30000 | 0 | 0 | 20000 | 1 | 0 | 0 | 2 | |
| declined | 70000 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | |
| Fred Anderson | won | 165000 | 7000 | 0 | 0 | 2 | 1 | 0 | 0 |
| pending | 0 | 5000 | 0 | 0 | 0 | 1 | 0 | 0 | |
| presented | 30000 | 0 | 5000 | 10000 | 1 | 0 | 1 | 1 | |
| declined | 65000 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | |
Вы также можете предоставить список агрегированных функций (aggfunctions), которые будут применяться к каждому значению:
table = pd.pivot_table(df,
index=["Manager", "Status"],
columns=["Product"],
values=["Quantity", "Price"],
aggfunc={"Quantity": len, "Price": [np.sum, np.mean]},
fill_value=0)
table
| Price | Quantity | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mean | sum | len | |||||||||||
| Product | CPU | Maintenance | Monitor | Software | CPU | Maintenance | Monitor | Software | CPU | Maintenance | Monitor | Software | |
| Manager | Status | ||||||||||||
| Debra Henley | won | 65000 | 0 | 0 | 0 | 65000 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| pending | 40000 | 5000 | 0 | 0 | 40000 | 10000 | 0 | 0 | 1 | 2 | 0 | 0 | |
| presented | 30000 | 0 | 0 | 10000 | 30000 | 0 | 0 | 20000 | 1 | 0 | 0 | 2 | |
| declined | 35000 | 0 | 0 | 0 | 70000 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | |
| Fred Anderson | won | 82500 | 7000 | 0 | 0 | 165000 | 7000 | 0 | 0 | 2 | 1 | 0 | 0 |
| pending | 0 | 5000 | 0 | 0 | 0 | 5000 | 0 | 0 | 0 | 1 | 0 | 0 | |
| presented | 30000 | 0 | 5000 | 10000 | 30000 | 0 | 5000 | 10000 | 1 | 0 | 1 | 1 | |
| declined | 65000 | 0 | 0 | 0 | 65000 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | |
Может показаться сложным собрать все это сразу, но как только вы начнете играть с данными и медленно добавлять элементы, то почувствуете, как это работает.
Мое общее практическое правило заключается в том, что после использования нескольких группировок (grouby) вы должны оценить, является ли сводная таблица (pivot table) полезным подходом.
После того, как вы сгенерировали свои данные, они находятся в DataFrame, поэтому можно фильтровать их, используя обычные методы DataFrame.
Если вы хотите посмотреть только на одного менеджера:
# https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.query.html
table.query('Manager == ["Debra Henley"]')
| Price | Quantity | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mean | sum | len | |||||||||||
| Product | CPU | Maintenance | Monitor | Software | CPU | Maintenance | Monitor | Software | CPU | Maintenance | Monitor | Software | |
| Manager | Status | ||||||||||||
| Debra Henley | won | 65000 | 0 | 0 | 0 | 65000 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| pending | 40000 | 5000 | 0 | 0 | 40000 | 10000 | 0 | 0 | 1 | 2 | 0 | 0 | |
| presented | 30000 | 0 | 0 | 10000 | 30000 | 0 | 0 | 20000 | 1 | 0 | 0 | 2 | |
| declined | 35000 | 0 | 0 | 0 | 70000 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | |
Мы можем просмотреть все незавершенные (pending) и выигранные (won) сделки:
table.query('Status == ["pending", "won"]')
| Price | Quantity | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mean | sum | len | |||||||||||
| Product | CPU | Maintenance | Monitor | Software | CPU | Maintenance | Monitor | Software | CPU | Maintenance | Monitor | Software | |
| Manager | Status | ||||||||||||
| Debra Henley | won | 65000 | 0 | 0 | 0 | 65000 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| pending | 40000 | 5000 | 0 | 0 | 40000 | 10000 | 0 | 0 | 1 | 2 | 0 | 0 | |
| Fred Anderson | won | 82500 | 7000 | 0 | 0 | 165000 | 7000 | 0 | 0 | 2 | 1 | 0 | 0 |
| pending | 0 | 5000 | 0 | 0 | 0 | 5000 | 0 | 0 | 0 | 1 | 0 | 0 | |
Я надеюсь, что этот пример показал вам, как использовать сводные таблицы в собственных наборах данных.
Схема с примером из Блокнота: