
На днях я использовал pandas для очистки грязных данных Excel, которые включали несколько тысяч строк с плохо отформатированными значениями валют. Когда я попытался выполнить очистку, то понял, что это немного сложнее, чем я предполагал. Случайно, пару дней спустя я подписался на ветку твиттера, которая пролила некоторый свет на возникшую проблему.
Данная статья суммирует мой опыт и описывает, как очистить грязные поля валюты и преобразовать их в числовые значения для дальнейшего анализа. Проиллюстрированные здесь концепции также могут применяться к другим типам задач очистки данных в pandas.
Оригинал статьи Криса тут.
Так выглядят грязные данные Excel:
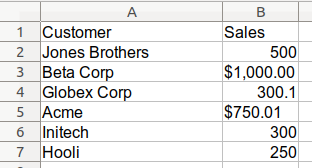
В этом примере данные представляют собой смесь значений с обозначением валюты $ и значений без обозначения валюты. Для небольшого примера, подобного этому, вы можете очистить его в исходном файле. Однако, когда у вас большой набор данных (с введенными вручную данными), у вас не будет другого выбора, кроме как начать с грязных данных и очистить их в pandas.
Прежде чем идти дальше, полезно просмотреть мою статью о типах данных (а тут перевод статьи на русский язык).
Фактически, работа над этой статьей заставила меня изменить мою исходную статью, чтобы уточнить типы данных, хранящиеся в столбцах object.
import pandas as pd
df_orig = pd.read_excel('https://github.com/dm-fedorov/pandas_basic/blob/master/%D0%B1%D1%8B%D1%81%D1%82%D1%80%D0%BE%D0%B5%20%D0%B2%D0%B2%D0%B5%D0%B4%D0%B5%D0%BD%D0%B8%D0%B5%20%D0%B2%20pandas/data/sales_cleanup.xlsx?raw=True')
df = df_orig.copy()
df
| Customer | Sales | |
|---|---|---|
| 0 | Jones Brothers | 500 |
| 1 | Beta Corp | $1,000.00 |
| 2 | Globex Corp | 300.1 |
| 3 | Acme | $750.01 |
| 4 | Initech | 300 |
| 5 | Hooli | 250 |
Я прочитал данные и сделал их копию, чтобы сохранить оригинал.
Первое, что я обычно делаю при загрузке данных, это проверяю типы:
df.dtypes
Customer object Sales object dtype: object
Неудивительно, что столбец Sales (Продажи) хранится как object. Знаки $ и , - это явные признаки того, что столбец Sales не является числовым. Скорее всего, мы захотим провести вычисления со столбцом, поэтому давайте попробуем преобразовать его в число с плавающей точкой.
В реальном наборе данных не так легко заметить, что в столбце есть нечисловые значения.
В моих данных я первым делом попытался использовать метод astype().
# здесь получим ошибку:
# df['Sales'].astype('float')
Трассировка исключения включает ValueError и показывает, что не удалось преобразовать строку $1,000.00 в число с плавающей точкой. Хорошо. Это легко исправить.
Давайте попробуем удалить символы $ и , с помощью str.replace():
df['Sales'] = df['Sales'].str.replace(',', '')
df['Sales'] = df['Sales'].str.replace('$', '')
df['Sales']
0 NaN 1 1000.00 2 NaN 3 750.01 4 NaN 5 NaN Name: Sales, dtype: object
Хм. Я не ожидал этого. По какой-то причине строковые значения были очищены, но другие значения преобразованы в NaN. Это большая проблема.
Честно говоря, именно такой результат я получил и потратил гораздо больше времени, чем следовало бы, пытаясь понять, что пошло не так. В конце концов я разобрался и расскажу о проблеме здесь, чтобы вы могли извлечь уроки из моей борьбы!
В ветке твиттера Теда Петру (Ted Petrou) и в комментарии Мэтта Харрисона (Matt Harrison) резюмировали мою проблему и показали несколько полезных фрагментов кода, которые я опишу ниже.
По сути, я предполагал, что столбец object содержит только строки. На самом деле столбец object может содержать смесь из нескольких типов данных.
Давайте посмотрим на типы данных в этом наборе:
df = df_orig.copy()
df['Sales'].apply(type)
0 <class 'int'> 1 <class 'str'> 2 <class 'float'> 3 <class 'str'> 4 <class 'int'> 5 <class 'int'> Name: Sales, dtype: object
Аааа! Это хорошо показывает проблему.
Код apply(type) выполняет функцию type для каждого значения в столбце. Как видите, некоторые значения являются числами с плавающей точкой, некоторые - целыми числами, а некоторые - строками. В целом столбец - это object.
Вот два полезных совета, которые я теперь добавляю в свой набор инструментов (спасибо Теду и Мэтту), чтобы выявить эти проблемы на ранних этапах процесса анализа.
Во-первых, мы можем добавить отформатированный столбец, показывающий каждый тип:
df['Sales_Type'] = df['Sales'].apply(lambda x: type(x).__name__)
df['Sales_Type']
0 int 1 str 2 float 3 str 4 int 5 int Name: Sales_Type, dtype: object
df
| Customer | Sales | Sales_Type | |
|---|---|---|---|
| 0 | Jones Brothers | 500 | int |
| 1 | Beta Corp | $1,000.00 | str |
| 2 | Globex Corp | 300.1 | float |
| 3 | Acme | $750.01 | str |
| 4 | Initech | 300 | int |
| 5 | Hooli | 250 | int |
Или вот более компактный способ проверить типы данных в столбце с помощью метода value_counts():
df['Sales'].apply(type).value_counts()
<class 'int'> 3 <class 'str'> 2 <class 'float'> 1 Name: Sales, dtype: int64
Я обязательно буду использовать этот прием в своем повседневном анализе при работе со смешанными типами данных.
Чтобы проиллюстрировать проблему и предложить решение, я покажу краткий пример подобной проблемы, используя только стандартные типы данных Python.
Сначала создайте числовую и строковую переменные:
number = 1235
number_string = '$1,235'
print(type(number_string), type(number))
<class 'str'> <class 'int'>
Этот пример похож на наши данные, у нас есть строка и целое число.
Если мы хотим очистить строку, чтобы удалить лишние символы и преобразовать ее в число с плавающей запятой:
float(number_string.replace(',', '').replace('$', ''))
1235.0
Отлично!
Что произойдет, если мы попробуем то же самое с нашим целым числом?
# здесь произойдет исключение:
# float(number.replace(',', '').replace('$', ''))
Вот в чем проблема. Мы получаем ошибку при попытке использовать строковые функции для целого числа.
Когда pandas пытается применить аналогичный подход, используя метод доступа str, он возвращает NaN вместо ошибки. Вот почему числовые значения преобразуются в NaN.
Решение - проверить, является ли значение строкой, а затем попытаться очистить его. В противном случае избегайте вызова строковых функций для числа.
Первый подход - написать собственную функцию и использовать метод apply.
def clean_currency(x):
""" Если значение является строкой, то удаляет символ валюты и разделители,
в противном случае - значение является числовым и может быть преобразовано.
"""
if isinstance(x, str):
return(x.replace('$', '').replace(',', ''))
return(x)
Эта функция проверяет, является ли указанное значение строкой, и, если да, удаляет все символы, которые нам не нужны. Если это не строка, то она вернет исходное значение.
Далее ее вызываем и преобразуем результат в число с плавающей точкой. Также я показываю столбец с типами:
df['Sales'] = df['Sales'].apply(clean_currency).astype('float')
df['Sales']
0 500.00 1 1000.00 2 300.10 3 750.01 4 300.00 5 250.00 Name: Sales, dtype: float64
df['Sales_Type'] = df['Sales'].apply(lambda x: type(x).__name__)
df['Sales_Type']
0 float 1 float 2 float 3 float 4 float 5 float Name: Sales_Type, dtype: object
df
| Customer | Sales | Sales_Type | |
|---|---|---|---|
| 0 | Jones Brothers | 500.00 | float |
| 1 | Beta Corp | 1000.00 | float |
| 2 | Globex Corp | 300.10 | float |
| 3 | Acme | 750.01 | float |
| 4 | Initech | 300.00 | float |
| 5 | Hooli | 250.00 | float |
Мы можем проверить атрибут dtypes:
df.dtypes
Customer object Sales float64 Sales_Type object dtype: object
Посмотрите на метод value_counts():
df['Sales'].apply(type).value_counts()
<class 'float'> 6 Name: Sales, dtype: int64
Все выглядит хорошо.
Мы можем продолжить работу с любыми математическими функциям, которые нужно применить к столбцу с продажами.
Прежде чем закончить, я приведу финальный пример того, как этого можно добиться с помощью лямбда-функции:
df = df_orig.copy()
df['Sales'] = df['Sales'].apply(lambda x: x.replace('$', '').replace(',', '')
if isinstance(x, str) else x).astype(float)
df['Sales']
0 500.00 1 1000.00 2 300.10 3 750.01 4 300.00 5 250.00 Name: Sales, dtype: float64
Лямбда-функция - это более компактный способ очистки и преобразования значения, но он может быть более трудным для понимания новыми пользователями. Мне лично нравится настраиваемая (custom) функция в этом случае. Особенно, если вам нужно очистить несколько столбцов.
Последнее предостережение, которое у меня есть, заключается в том, что вам все равно нужно понять свои данные, прежде чем выполнять эту очистку. Я предполагаю, что все значения продаж указаны в долларах. Это предположение может быть неверным. Если значения представлены в разных валютах, то потребуется разработать более сложный подход к очистке для преобразования в согласованный числовой формат.
Модуль Pyjanitor имеет функцию, которая позволяет конвертировать валюту и может быть полезным для более сложных задач.
После того, как я опубликовал статью, получил несколько советов об альтернативных способах решения.
Первое предложение заключалось в использовании регулярного выражения для удаления нечисловых символов из строки.
df = df_orig.copy()
df
| Customer | Sales | |
|---|---|---|
| 0 | Jones Brothers | 500 |
| 1 | Beta Corp | $1,000.00 |
| 2 | Globex Corp | 300.1 |
| 3 | Acme | $750.01 |
| 4 | Initech | 300 |
| 5 | Hooli | 250 |
df['Sales'] = df['Sales'].replace({'\$': '', ',': ''}, regex=True).astype(float)
df['Sales']
0 500.00 1 1000.00 2 300.10 3 750.01 4 300.00 5 250.00 Name: Sales, dtype: float64
Этот подход использует метод Series.replace(). Он очень похож на подход с заменой строки, но на самом деле этот код правильно обрабатывает нестроковые значения.
Иногда бывает сложно понять регулярные выражения. Тем не менее, это решение простое и я без колебаний использую его в реальном приложении. Спасибо Serg за указание на это.
Другая альтернатива, указанная Иэном Динвуди (Iain Dinwoodie) и Serg, - преобразовать столбец в строку и безопасно использовать str.replace().
Сначала мы читаем данные и используем аргумент dtype в функции read_excel, чтобы заставить исходный столбец данных сохраниться в виде строки:
df = pd.read_excel('https://github.com/dm-fedorov/pandas_basic/blob/master/%D0%B1%D1%8B%D1%81%D1%82%D1%80%D0%BE%D0%B5%20%D0%B2%D0%B2%D0%B5%D0%B4%D0%B5%D0%BD%D0%B8%D0%B5%20%D0%B2%20pandas/data/sales_cleanup.xlsx?raw=True', dtype={'Sales': str})
df.head()
| Customer | Sales | |
|---|---|---|
| 0 | Jones Brothers | 500 |
| 1 | Beta Corp | $1,000.00 |
| 2 | Globex Corp | 300.1 |
| 3 | Acme | $750.01 |
| 4 | Initech | 300 |
Можем быстро это проверить:
df['Sales'].apply(type).value_counts()
<class 'str'> 6 Name: Sales, dtype: int64
Затем примените очистку и преобразование типов:
df['Sales'] = df['Sales'].str.replace(',','').str.replace('$','').astype('float')
df['Sales']
0 500.00 1 1000.00 2 300.10 3 750.01 4 300.00 5 250.00 Name: Sales, dtype: float64
Поскольку все значения хранятся в виде строк, этот код работает правильно и не преобразует некоторые значения в NaN.
Тип данных object обычно используется для хранения строк. Однако вы не можете однозначно предполагать, что все типы данных в столбце object будут строками. Это может быть особенно запутанным при загрузке грязных данных о валюте, которые могут включать числовые значения с символами, а также целые числа и числа с плавающей точкой.
Вполне возможно, что наивные подходы к очистке непреднамеренно преобразуют числовые значения в NaN. В этой статье показано, как использовать пару уловок, чтобы идентифицировать отдельные типы в столбце object, очищать их и преобразовывать в соответствующее числовое значение. Надеюсь, это оказалось полезным.